
1. What is the difference between expired and obsolete backup.
Expire mean, the backup piece is not available at the physical location .
Obsolete backup mean, That backup piece is not required any more.
2. What is block change tracking?
Usually when we take incremental backup, It doesn’t have any information , about which blocks has been changed since last backup. It scan all the blocks(all the data), then take necessary backup. And scanning all the blocks, takes lot of time, when db size is large.
But if we enable block change tracking. RMAN will be aware of which blocks got changed and it will just take backup of those blocks(without scanning all the blocks).
3. How block change tracking works internally?
block change tracking file, stores the changes in bitmap. i.e there will be one bitmap (1 or 0 ) for each chunk of 32k sizeI ( i.e 4 contagious blocks of 8k size). So even if only one block is changed out of those 4 blocks , then the bitmap will also changed . So rman will consider that as changed chunk, and incremental will take that backup.
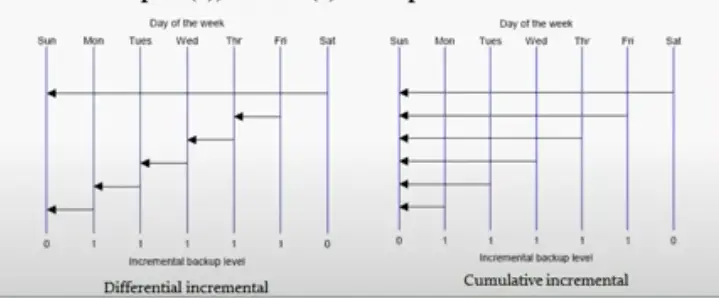
4. What is the difference between differential backup and Cumulative backup in incremental backup?
Differential Backup:
A differential backup, which backs up all blocks changed after the most recent incremental backup at level 1 or 0.
Cumulative Backup:
A cumulative backup, which backs up all blocks changed after the most recent incremental backup at level 0( i.e full backup).
So cumulative backup size will be larger. But restore /recover will be quick.
5. Can we take RMAN backup when the database is down?
For RMAN backup , database has to be in mount or open state. For cold backup only the database has to be down completely.
6. What happens when we put the database in hot backup mode i.e alter database begin backup? Why it generates lot of redo?
- DBWn checkpoints the tablespace (writes out all dirty blocks as of a given SCN)
- CKPT stops updating the Checkpoint SCN field in the datafile headers and begins updating the Hot Backup Checkpoint SCN field instead
- LGWR begins logging full images of changed blocks the first time a block is changed after being written by DBWn
Why lot of redo?
Lets say
Full block image logging during backup eliminates the possibility that the backup will contain unresolvable split blocks. To understand this reasoning, you must first understand what a split block is. Typically, Oracle database blocks are a multiple of O/S blocks. For example, most Unix filesystems have a default block size of 512 bytes, while Oracle’s default block size is 8k. This means that the filesystem stores data in 512 byte chunks, while Oracle performs reads and writes in 8k chunks or multiples thereof. While backing up a datafile, your backup script makes a copy of the datafile from the filesystem, using O/S utilities such as copy, dd, cpio, or OCOPY. As it is making this copy, your process is reading in O/S-block-sized increments. If DBWn happens to be writing a DB block into the datafile at the same moment that your script is reading that block’s constituent O/S blocks, your copy of the DB block could contain some O/S blocks from before the database performed the write, and some from after. This would be a split block. By logging the full block image of the changed block to the redologs, Oracle guarantees that in the event of a recovery, any split blocks that might be in the backup copy of the datafile will be resolved by overlaying them with the full legitimate image of the block from the archivelogs. Upon completion of a recovery, any blocks that got copied in a split state into the backup will have been resolved by overlaying them with the block images from the archivelogs. All of these mechanisms exist for the benefit of the backup copy of the files and any future recovery. They have very little effect on the current datafiles and the database being backed up. Throughout the backup, server processes read datafiles DBWn writes them, just as when a backup is not taking place. The only difference in the open database files is the frozen Checkpoint SCN, and the active Hot Backup Checkopint SCN.
7. What is a snapshot control file?
the snapshot controlfile is a backup creates before the actual backup starts in order to have a ‘read consistent’ view of the controlfile during the backup and during resync catalog.
This snapshot controlfile ensures that backup is consistent to point in time . So if you add a tablespace after the backup has been started, Then the new file will not be backed up.
8. What is the difference between validate and crosscheck command?
Validate backup set – checks whether backup sets can be restored or not.
crosscheck – go through the headers of the specified file, to check if they are on disk or tape.
9. what is the use of CONTROL_FILE_RECORD_KEEP_TIME?
This parameter defines, for how many days we want to keep the backup records (reusable) in the controlfile.
10. should we set “configure controlfile autobackup” to on or off ? and what is its significance? What is the default value?
It should be on always.
11.Can we restore a database from obsolete backup?
Yes we can restore a database from obsolete backup. For that we need to catalog those file explictly.
12.How can we take rman backup in parallel?
Yes we can. Either by mentioned the number of channels or using the parallel parameter.
13. What are the different types of retention policy? Explain about them.
Recovery Window based retention policies.
In the recovery window, Oracle checks the current backup and looks for its relevance backwards in time.
Lets say you have set recovery window of 7 days. So 7 days recovery window doesn’t mean that it will delete copies older than 7 days. It will retain the backups in such a manner that, you should be able to recover your database to any point in last 7 days.
Example – > configure retention policy to recovery window of 7 days;
Here our recover window is 7 days .
Now assume that you started on July 1st and have taken backups on the 8th, 15th, 22nd and 29th of July. Assuming the current date is the 25th of July, according to the recovery window of seven days, the point of recoverability goes up to the 18th of July. This means that to ensure the recoverability, the backup taken on 15th will be kept by Oracle so that you can recover up to that point.
Redundancy Based retention policies:
A redundancy-based retention policy specifies how many backups of each datafile must be retained. After that the older backup will be obsolete.
CONFIGURE RETENTION POLICY TO REDUNDANCY 2;
No retention policy:
Means the backups will not be obsolete at all.
CONFIGURE RETENTION POLICY TO NONE;
14. What happens when we open the database in resetlog?
15. What is an incarnation number?
When we open the database in resetlog , a new incarnation number is created. We can a new version of the database is created.
The log sequence number resets to 1 and the online redologs gets a new timestamp and scn.
16. What is the purpose of resync catalog command?
17. What is the meaning of the setting configure backup optimization on in RMAN?
18. Difference between backup piece and backup set?
Backup Set
Logical structure where the backup is stored. It is a logical container. A backup set can store one or multiple database files, spfiles, control files, etc. Do not think physically. One backup set can be stored in one or multiple files. Each of those files is called a backup piece. Usually, one backup set has only one backup piece.
Backup Piece
Physical structure where the backup is stored. A backup set is composed by one or more physical binary pieces. If you backup to disk, each file generated is a backup piece.
19. How can i take rman backup to multiple directory is local file sytem?
Yes we can do that.
20. What is the difference between maxpiece size and maxset size?
MAXPIECESIZE – Limits the size of each backup piece.
MAXSETSIZE – Maximum size of a backup set. Please remember, the maxsetsize value should be larger than the size of your largest data file.
21. What are things we can do to improves the performance of rman backup?
use of more number of channels
parallelism
multisection size
22. Let’s say there is a requirement that ,Your daily rman backup need to be completed within 40 min . If it exceeds backup should be stopped automatically? Can we do that ?
23. How can i take rman backup of spfile?
24. What is an image copy in rman?
An Image copy backup are exact copies of the datafiles including the free space. They are not stored in RMAN backup pieces but as actual datafiles, therefore are a bit-for-bit copy.
This is usually helpful, when you want to move the database from non-asm to asm file system.
25. How can we recover from loss of online redolog?
In this case, first you need to find, what is the stauts of redolog file that is lost/corrupt. Your action plan depends upon the redolog file status.

26. What is incomplete recovery? How it works? What are the Different types of incomplete recovery scenarios?
Incomplete means you dont have all the redo or archives to recover all the commited transactions. I.e we need to/want to re recover the database to a specific point in time in past. So alternatively incomplete recovery is called as point in time recovery.
We do incomplete Recovery in 2 cases.
- You don’t have all the redo required to perform a complete recovery. You’re missing either archived redo log files or online redo log files (current or unarchived) that are required for complete recovery. This situation could arise because the required redo files are damaged or missing.
- You purposely want to roll the database back to a point in time. For example, you would do this in the event somebody accidentally truncated a table and you intentionally wanted to roll the database back to just before the truncate table command was issued.
27. Can we restore one table or table partition from rman backup? Explain how it works internally?
Yes from 12c onwards we can do it.
28.When we duplicate the database using rman active duplication method, does the dbid gets changed for the new database?
29. Can we change the dbid to a value of our own choice?
Yes we can do it.
30. What is the use of nofilenamecheck command in rman duplication command?
/oracle/dbs/system_prod1.dbf
/oracle/dbs/users_prod1.dbf
/oracle/dbs/rbs_prod1.dbf
Assume that you want to duplicate this database to host2, which has the same file system /oracle/dbs/*, and you want to use the same filenames in the duplicate database as in the source database. In this case, specify the NOFILENAMECHECK option to avoid an error message. Because RMAN is not aware of the different hosts, RMAN cannot determine automatically that it should not check the filenames.If duplicating a database on the same host as the source database, then make sure that NOFILENAMECHECK is not set. Otherwise, RMAN may signal the error.
31. Suppose you are running a active duplication from a database of 40 TB. And after 95 percent of cloning is completed, it failed due to network error? Do we need to start the cloning again from start?
32. We need to duplicate a bigfile tablespace of size 500GB. Can we use multiple channels to improves the speed? Is there any other option to improve the performance?
During duplication, only one channel is allocated for each datafile. So even if we allocate 5 channels, only one channels will be used to do the duplication. So it will not improve the speed.
So in this case we can use the section size attribute in the duplicate command . Let’s say the section size we defined is 1G and we have 10 channels. So during duplication the datafile will be broken into section size of 1GB and each channel will process one section size ( i.e all 10 channels will be active in parallel with each processing 1GB data)
COMMAND – >
RMAN> duplicate target database to test_db from active database section size 1024M;
33. Difference between restore and recover?
- Restore: It is the act that involves the restoration of all files that will be required to recover your database to a consistent state, for example, copying all backup files from a secondary location such as tape or storage to your stage area
- Recovery: It is the process to apply all transactions recorded in your archive logs, rolling your database forward to a point-in-time or until the last transaction recorded is applied, thus recovering your database to the point-in-time you need
34. Someone deleted some data from a table 5 mins back. Database is archivelog mode , But flashback mode is not enabled. Can we retrieve the table data ?
Yes we can recover that table , only if undo is enabled.
35.Can i take the fullbackup from primary and incremental backup from standby?
Yes we can take backup from standby and primary database, as both the databases are same and have the same dbid.
36.Have you heard of Zero data loss Recovery Appliance(ZDLRA)?
37.Can we duplicate a database by skipping few tablespaces?
Yes we can skip few tablespaces. But we cannot skip system, sysaux, undo or any tablespace containing sys objects.
38. For a schema, its tables are under tablespace DATA and its indexes are under tablespace IDX. Now if i run rman duplicate by skipping IDX tablespace, What will happen? Will it work?
So we cannot skip IDX tablespace. As this is not a self contained tablespace i.e there is a dependency between objects in DATA and IDX tablespace. So either we need to skip both or we need to duplicate both .
39.How can we check the integrity of rman backup?
Validate command can be used to check the integrity of the rman backup?
40.Different encryption methods offered by rman?
41.Different between backupset and image copy?
42.What is difference between consistent backup and inconsistent backup?
Consistent Backup
A consistent backup of a database or part of a database is a backup in which all read/write datafiles and control files are checkpointed with respect to the same system change number (SCN). Oracle determines whether a restored backup is consistent by checking the datafile headers against the datafile header information contained in the control file
IN-Consistent Backup
An inconsistent backup is a backup in which all read/write datafiles and control files have not been checkpointed with respect to the same SCN. For example, one read/write datafile header may contain an SCN of 100 while other read/write datafile headers contain an SCN of 95 or 90. Oracle cannot open the database until all of these header SCNs are consistent, that is, until all changes recorded in the online redo logs have been applied to the datafiles on disk.
43.What is RTO and RPO?
44. Currently we have 30 days of archive logs present , so used delete archivelog all completed before ‘sysdate-3’ to delete files older than 3 days. But this command is not deleting files older than 14 days. Why?
You need to check your CONTROL_FILE_KEEP_RECROD_TIME. If this is set 14 days. then Only 14 days archive information will be stored in the control_file. If archive logs are older than 14 days, its related information will be removed from control_file.
So when we use rman it gets data from controlfile. As only 14 days information is present in control_file. RMAN delete command will ignore files older than 14 days.
Default value of CONTROL_FILE_KEEP_RECORD_TIME is 7 days.
45. Explain how rman works internally , when you are running rman database backup?
Lets say you connected as rman to target db and run backup database ;
rman target /
RMAN> backup database;
- RMAN makes the bequeath connection with the target database.
- It then connect to internal database user sys.RMAN and spawn multiple channel as mentioned in script.
- Then RMAN make a call to sys.dbms_rcvman to request database schema information from controlfile( like datafile info,scn)
- After getting the datafile list, it prepare for backup.To guarantee consistency it either builds or refreshes the snapshot control file.
- Now RMAN make a call to sys.dbms_backup_restore package to create backup pieces.
- If controlfile autobackup is set to on, then it will take backup of spfile and controfile to backupset.
- During backup, datafile blocks are read into a set of input buffers, where they are validated/compressed/encrypted and copied to a set of output buffers. The output buffers are then written to backup pieces on either disk or tape (DEVICE TYPE DISK or SBT).
46. Rman full database started at 5:00 AM , while it is still running at 5.30 AM , a new datafile has been added. The backup completed at 6:00 AM. So will the new datafile will be part of this rman backup set?
No it will not be added in the rman backup.
47. What are the different phases of RMAN backup.
- Read PhaseA channel reads blocks from disk into input I/O buffers.
- Copy PhaseA channel copies blocks from input buffers to output buffers and performs additional processing on the blocks.
- Write PhaseA channel writes the blocks from output buffers to storage media. The write phase can take either of the following mutually exclusive forms, depending on the type of backup media:
48. Who updates the block change tracking file(BCT) and how it does?
CTWR background process updates the block change tracking file.
49. Lets say I have taken a full backup at 5 AM. and after 2 hour ( 7 AM ) I added 2 datafiles. And now At 9 am , the db crashed/corrupted. So i need to restore/recover the database. Can i use the full backup to restore/recover the database including those datafiles which were added later?
Yes we will restore the full backup , then recover using the archivelogs to the current point.
50. How can i recover from undo block corruption?
First you need to find which datafile and block is corrupted.
V$DATABASE_BLOCK_CORRUPTION , and then connect with rman and run block recover command.
51. What is the relation between large pool size and rman backup?
52. How can we take RMAN cold backup ?
if the database is no archivelog mode, then also you can startup the database in mount stage and take backup.
53. Suppose someone dropped a table mistakenly in production database. What will be your immediate action plan to recover that table?
54. What is backup optimization in RMAN?