
1. Why we are using vip in RAC? Because before 10g, there were no concept of vip.
If user connected to the INSTANCE using physical ip, and if the node goes down, then there is no way for the user to know whether node is available or not. So it need to wait for a long time, till it gets timed out by the network.
However If i use logical vip( on top of physical vip), then if node goes down, then CRS will failover this vip to other surviving node. And the user will get the connection error quickly( like TNS no listener available ).
2. If i have a 8 node RAC, then how many scan listeners are required?
3 SCAN listeners sufficient for any RAC setup. It is not mandatory for scan listener to run on all the nodes.
3. How SCAN knows which node has least load?
Load balance Advisory provides load information to scan.
4. Explain how client connection is established in RAC database ?
LREG process on each instances registers the database service of the node with default local listener and scan listener. The listeners store the workload information of each node.
So when client tries to connect using scan_name and port,
- scan_name will be resolved through DNS , which will redirect to 1st scan ip ( out of 3).
- the client will connected to the respective scan listener
- The scan listener compares the work load of both the instances and if scan determines that node1 has least load , then scan listener send the vip address and port details of that particular nodes local listener to client.
- Now client connects to that local listeners and a dedicated server process is created
- Client connection becomes successful and it starts accessing the database.
5. What current block and CR block and PI in RAC?
Data block requests from global cache are of two types.
current block(cur) – > When we want to update a data, oracle must locate the most recent version of the block in cache, it is known as current block
consistent read(CR) – > When we want to read a data, then only committed data will be provided( with help of undo). that is known as consistent read.
Past image(PI) – When node A wants to updates the block, which is present on node B and node B has also updated the block , then node B will send the current copy of the block to Node A, it will keep a past image( PI) of the block , until it is written to the disk. Once commit happens on node B for that transaction or when checkpoint happens , the PI images will be flushed to disk.
There can be multiple CR blocks, But there will be always one Current block.
There can multiple scur(shared current) , But only xcur( exclusive current).
6. What is gc buffer busy wait?
Mean a session is trying to access a buffer in buffer cache, But that particular buffer is currently busy with global cache operation.
So during that time gc buffer busy wait will happen.
Example –
- Let’s say session A want to access block id 100 , But currently that block is in buffer cache of session B.
- So session A requested session B LMS process to transfer the block.
- While transfer is going on , session B also tried to access that block. But as already that block/buffer is already busy in global cache operation. Session B has to wait with wait event, gc buffer busy wait.
Reasons – Concurrency related, Right hand index growth.
other reason might be lack of cpu, slow interconnect .
8. What are some RAC specific parameters ?
- undo_tablespaces
- cluster_database
- cluster_interconnects
- remote_listener
- thread
- cluster_database_instances
9. Why RAC has separate redo thread for each node?
In RAC, each instance have their own lgwr process , So there has to be separate online redolog for each instance ( called as thread), So that lgwr will write to the respective redo log.
10. Why RAC has separate undo tablespace for each node?
If we keep only one undo, then it need more coordination between nodes and it will impact the traffic between the instances.
11. Explain about local_listener and remote_listener parameter in RAC?
In RAC, local_listener parameter points to node vip and remote_listener is set to the scan
Purpose of Remote Listener is to connect all instances with all listeners so the instances can propagate their load balance advisories to all listeners. Listener uses the advisories to decide which instance should service client request. If listener get to know from advisories that its local instance is least loaded and should service client request then listener passes client request to local instance. If local instance is over loaded then listener can use TNS redirect to redirect client request to a less loaded instance means remote instance. This Phenomenon is also called as Server Side Load balancing.
12. What are local registry and cluster registry?
13. What is client side load balancing and server side load balancing?
14. What are the RAC related background processes?
LMON –
- (Global Enqueue Service Monitor) It manages global enqueue and resources.
- LMON detects the instance transitions and performs reconfiguration of GES and GCS resources.
- It usually do the job of dynamic remastering.
LMD – >
- referred to as the GES (Global Enqueue Service) daemon since its job is to manage the global enqueue and global resource access.
- LMD process also handles deadlock detection and remote enqueue requests.
LCK0 -(Instance Lock Manager) > This process manages non-cache fusion resource requests such as library and row cache requests.
LMS – ( Global Cache Service process) – >
- Its primary job is to transport blocks across the nodes for cache-fusion requests.
- GCS_SERVER_PROCESSES –> no of LMS processes specified in init. ora parameter.
- Increase this parameter if global cache is very high.
ACMS:
- Atomic Controlfile Memory Service.
- ensuring a distributed SGA memory update is either globally committed on success or globally aborted if a failure occurs.
RMSn: Oracle RAC Management Processes (RMSn)
It usually helps in creation of services, when a new instance is added.
LMHB
- Global Cache/Enqueue Service Heartbeat Monitor
- LMHB monitors the heartbeat of LMON, LMD, and LMSn processes to ensure they are running normally without blocking or spinning
15. What is TAF?
TAF provides run time failover of connection. There are different options we can mention while creating taf policy.
Let’s say we created TAF with select option. Now Suppose a user connecting to using the taf and running a select statement. While select statement is running, the node on which the select statement running crashed. So the select statement will be transparently failed over to other node and select statement will be completed and results will be fetched.
16. What is Flex Cluster introduced in oracle 12c?
17. ASM is running , but the database is not coming up? What might be the issue?
18. Can we start crs in exclusive mode? and its purpose?
19. If crs is not coming up , then what are things you will start looking into?
20. What data we need to check in vmstat and iostat output?
21. Explain different ways to find master node in oracle rac?
- Grep occsd Log file. [oracle @ tadrac1]: /u1/app/../cssd >grep -i “master node” ocssd.log | tail -1. …
- Grep crsd log file. [oracle @ tadrac1]: /u1/app/../crsd>grep MASTER crsd.log | tail -1.
- Query V$GES_RESOURCE view.
- ocrconfig -showbackup. The node that store OCR backups is the master node.
22. What is cache fusion in oracle RAC? and its benefits?
23. Explain split brain in oracle RAC.
24. Difference between crsctl and srvctl?
25. I want to run a parallel query in rac database, But I need to make sure that, the parallel slave processes will run only on node where i am running the query and it will not move to other node.
We can set Parallel_force_local parameter to TRUE at session level and then run the parallel query. All the px processes will run only on that node.
26. My clusterware version is 11gr2 , can i install oracle 12c database? is the viceversa possible( means clusteware version 12c and oracle database version 11g?)?
My clusterware version can be same or higher than the the database version. But a 12c database will not work on 11g grid.
27. What are the storage structures of a clusterware?
2 shares storage structure – OCR , VD
2 local storage structure – OLR, GPNP profile.
28. What is OLR and why it is required?
While starting clusterware, it need to access the OCR , to know which resources it need to start. However the OCR file is stored inside ASM, which is not accessible at this point( because ASM resource also present in OCR file.
To avoid this, The resources which need to be started on node is stored in operating file system called as OLR ( Oracle local registry). Each node will have their OLR file.
So when we start the clusterware, this file will be accessed first.
29. What is OCR and what it contains?
OCR is the central repository for CRS, which stores the metadata, configuration and state information for all cluster resources defined in clusterware.
node membership information
status of cluster resources like database,instance,listener,services
ASM DISKGROUP INFORMATION
Information ocr,vd and its location and backups.
vip and scan vip details.
30. Who updates OCR and how/when it gets updated?
OCR is updated by clients application and utilities through CRSd process.
1.tools like DBCA,DBUA,NETCA,ASMCA,CRSCTL,SRVCTL through CRsd process.
2. CSSd during cluster setup
3.CSS during node addition/deletion.
Each node maintains a copy of OCR in the memory. Only one CRSd(master) , performs read, write to the OCR file . Whenever some configuration is changed, CRSd process will refresh the local OCR cache and remote OCR cache and updates the OCR FILE in disk.
So whenever we try get cluster information using srvctl or crsctl , then it uses the local ocr for fetching the data . But when it modify , then through CRSd process, it will updates the ocr physical file).
31. What is the purpose of Voting disk?
Voting disk stores information about the nodes in the cluster and their heartbeat information. Also stores information about cluster membership.
32. Why we need voting disk?
Oracle Clusterware uses the VD to determine which nodes are members of a cluster. Oracle Cluster Synchronization Service daemon (OCSSD) on each cluster node updates the VD with the current status of the node every second. The VD is used to determine which RAC nodes are still in the cluster should the interconnect heartbeat between the RAC nodes fail.
33. What is GPNP profile?
Grid plug and play(GPNP) file is small xml file present at os local file system . Each node have their owner GPNP file.
GPNP file is managed by GPNP daemon.
It stores information like asm diskstring , asm spfile which are required to start the cluster.
34. What are the software stacks in oracle clusterware?
From 11g onward, there are two stacks for clusterware is CRS.
- lower stack is high availability cluster service stack ( managed by ohasd daemon)
- upper stack is CRSD stack ( managed by CRSd daemon)
35. What are the role of CRSD,CSSD,CTSSD, EVMD, GPNPD
CRSD – Cluster ready service daemon – It manages the cluster resources , based on OCR information. It includes start,stop and failover or resource. It monitors database instance, asm instance ,listeners, services and etc on and automatically restarts them when failure occurs.
CSSD – > Cluster syncronization service – It manages the cluster configuration like, which nodes are part of cluster etc. . When a node is added or deleted, it inform the same about this other nodes. It is also responsible for node eviction if situation occurs.
CSSD has 3 processes – >
the CSS daemon (ocssd),
the CSS Agent (cssdagent), The cssdagent process monitors the cluster and provides input/output fencing.
the CSS Monitor (cssdmonitor) – Monitors internode cluster health
- CTSSD – > Provides time managment for cluster service. If ntp is running on server, then CTSS runs in observer mode.
- EVMD – > Event Manger , Is a background process that publishes Oracle Clusterware events and manages message flow between the nodes and logs relevant information to log file.
- oclskd -> Cluster Kill Daemon – > Is used by CSS to reboot a node based on requests from other nodes in the cluster
- Grid IPC daemon (gipcd): Is a helper daemon for the communications infrastructure
- Grid Plug and Play (GPNPD): GPNPD provides access to the Grid Plug and Play profile, and coordinates updates to the profile among the nodes of the cluster to ensure that all of the nodes node have the most recent profile.
- Multicast Domain Name Service (mDNS): Grid Plug and Play uses the mDNS process to locate profiles in the cluster, as well as by GNS to perform name resolution.
- Oracle Grid Naming Service (GNS): Handles requests sent by external DNS servers, performing name resolution for names defined by the cluster.
36. ASM spfile is stored inside ASM diskgroup, So how clusterware starts the ASM instance( as asm instance needs asm file startup)?
So here is the sequence of cluster startup.
ohasd is started by init.ohasd
ohasd accesses OLR file(stored in local file system) to initialize ohasd process.
ohasd starts gpnpd and cssd.
cssd process reads gpnp profile to get information like asm_diskstring, asm spfile ..
cssd scans all the asm disk headers and find the voting disk location and read using kfed command and it joins the cluster.
To read the spfile, It is not necessary to open the disk. All information necessary for this stored in the asm disk header. OHASD reads the header of asm disk containing spfile( this spfile location is retrieved from gpnp profile). and contents of the spfile are read using kfed command. Using this asm spfile, ASM instance is started.
Now asm instance is up, OCR can be accessed, as it is inside ASM diskgroup. So OHASD will star the CRSD.
So below are the 5 important files it access.
FILE 1 : OLR ( ORACLE LOCAL REGISTRY ) ——————————-> OHASD Process
FILE 2 :GPNP PROFILE ( GRID PLUG AND PLAY ) ————————> GPNPD process
FILE 3 : VOTING DISK —————————————————————-> CSSD Process
FILE 4 : ASM SPFILE ——————————————————————> OHASD Process
FILE 5 : OCR ( ORACLE CLUSTER REGISTRY ) ——————————> CRSD Process
37. Explain RAC startup sequence?
Init process spawns init.ohasd(inside /etc/init) , which start the OHASd process,
Go through the below diagram .
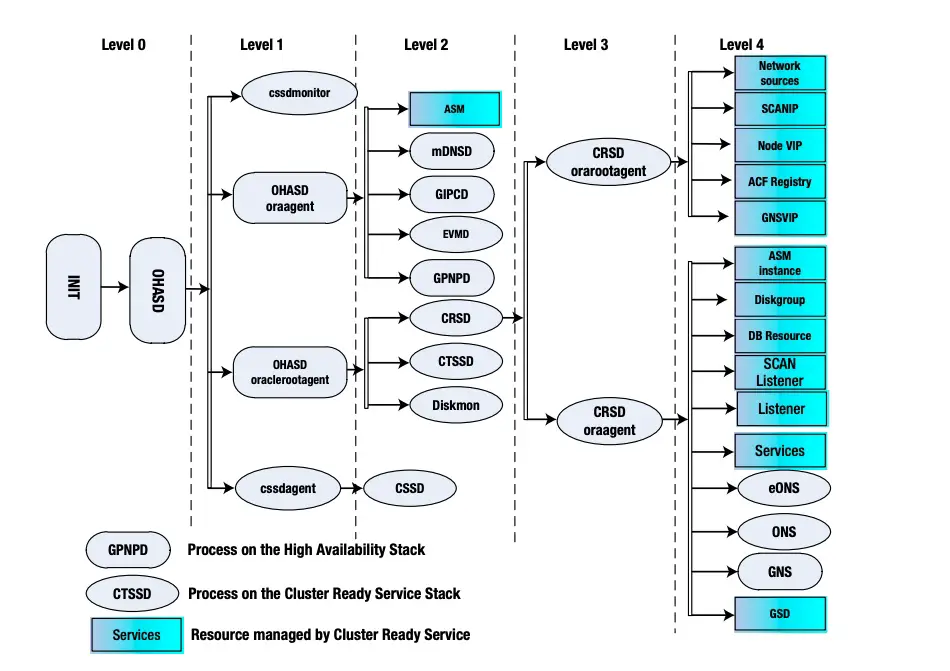
38. What is GES and GCS?
GES and GCS are two important parts of GRD(Global resource Directiory)
GES and GES have a memory structure in Global resource , which is distributed across the instance. It is part stored in shared pool section.
Global enqueue service ( GES) handles the enqueue mechanism in oracle RAC. It performs concurrency control on dictonary cache, library cache locks and transactional locks. This mechanism ensures that all the instances in cluster, know the locking status of each other . i.e If node 1 want to lock a table , then it need to know what type of lock is present in other node. Background processes like LCK0, LMD and LMON .
Glocal Cache Service(GCS) handles the block management. It maintains and tracks the location and status of blocks. It is responsible for block transfer across instances. LMS is primary background process .
39. What is dynamic remastering?
Mastering of a block means, master instance will keep track of the state of blocks until the remastering happens due of few of the scenarios like instance crash etc.
GRD stores useful infor like data block address, block status, lock information, scn, past image etc. Each instance have some of the GRD data in their SGA. i.e any instance which is master of the block or resource , will maintain the GRD of that resource in their SGA.
Mastering of a resource is decided based on the demand. If a particular resource is mostly accessed from node 1, then node1 will become the master of that resource. And if after some time if node 2 is heavily accessing the same resource, then all the resource information will be moved the node2 GRD.
LMON, LMD, LMS are responsible for dynamic remastering.
Remastering can happen due to below scenarios.
- Resource affinity – > GCS keeps tracks of the number of GCS request per instance and per objects . If one instance is heavily accessing the object blocks, compare to other nodes, Then gcs can take decision to migration all the object resource to the heavily accessed instance.
- Manually remastering – > We can manually remaster a object
- Instance crash – > If instance is crashed, the the its GRD data will be remastering to the existing instances in cluster.
40. How instance recovery happens in oracle RAC?
When any one of the instance is crashed in RAC, then this node failure is detected by the surviving instances. Now the GRD resouces will be distributed across the existing instances. The instance which first detects the crash, will the start the online redo log thread of the crashed instance. The SMON of that instance, will read the redo to do rollforward ( i.e to apply both committed and noncommited data). Once rollforward is done, it will rollback the uncommited transactions using UNDO tablespace of the failed instance.
Sequence
- Normal RAC operation, all nodes are available.
- One or more RAC instances fail.
- Node failure is detected.
- Global Cache Service (GCS) reconfigures to distribute resource management to the surviving instances.
- The SMON process in the instance that first discovers the failed instance(s) reads the failed instance(s) redo logs to determine which blocks have to be recovered.
- SMON issues requests for all of the blocks it needs to recover. Once all blocks are made available to the SMON process doing the recovery, all other database blocks are available for normal processing.
- Oracle performs roll forward recovery against the blocks, applying all redo log recorded transactions.
- Once redo transactions are applied, all undo records are applied, which eliminates non-committed transactions.
- Database is now fully available to surviving nodes.
41. What is TAF in oracle RAC?
BASIC
PRECONNECT
SELECT FAILOVER
SESSION FAILOVER
42. Can we have multiple SCAN(name) in a RAC?
From 12c onwards, We can have multiple scan with different subnets. As part of installation only scan will be configured. Post installation we need to configure another SCAN with different subnet( If required).
43. In RAC, where we define the SCAN?
We can define SCAN with below 2 option.
- Using corporate DNS
- Using Oracle GNS( Grid naming service)
44. What g stand for in views like gv$session , gv$sql etc.?
45. What is load balancing advisory?
46. What is ACMS?
47. What are some RAC related wait events?
48. What is the role of LMON background process?
49. What is gc cr 2 way and gc cr 3 way?
50. What is HAIP?
HAIP, High Availability IP, is the Oracle based solution for load balancing and failover for private interconnect traffic. Typically, Host based solutions such as Bonding (Linux)is used to implement high availability solutions for private interconnect traffic. But, HAIP is an Oracle solution for high availability.
Essentially, even if one of the physical interface is offline, private interconnect traffic can be routed through the other available physical interface. This leads to highly available architecture for private interconnect traffic.
The ora.cluster_interconnect.haip resource will pick up a highly available virtual IP (the HAIP) from “link-local” (Linux/Unix) IP range (169.254.0.0 ) and assign to each private network. With HAIP, by default, interconnect traffic will be load balanced across all active interconnect interfaces. If a private interconnect interface fails or becomes non-communicative, then Clusterware transparently moves the corresponding HAIP address to one of the remaining functional interfaces.
$ crsctl stat res ora.cluster_interconnect.haip -init
NAME=ora.cluster_interconnect.haip
TYPE=ora.haip.type
TARGET=ONLINE STATE=ONLINE on dbhost1
Here if you , while installing, we have given private interrconnect as 192.168.1.0 ( ens225) , But while starting the cluster, a new vip as 169.254* has been assigned, so gv$cluster_interconnect shows ip_address as 169.254*.
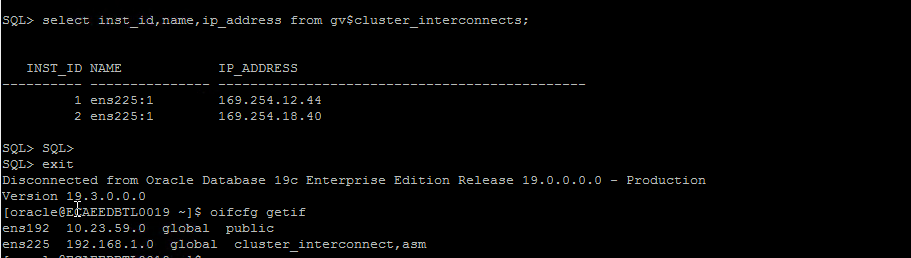
NOTE – For the HAIP, to failover to other interconnect, there has to be another physical interconnect,
51. What is node eviction and in which scenarios node eviction happens?
Ocssd.bin is responsible to ensure the disk heartbeat as well as the network heartbeat.
There’s a maximum delay in both heartbeats , The delay of network heartbeat is called MC(Misscount), The disk heartbeat delay is called IOT (I/O Timeout). this 2 All parameters are in seconds , By default Misscount < Disktimeout.
[grid@Linux-01 ~]$ crsctl get css misscount
CRS-4678: Successful get misscount 30 for Cluster Synchronization Services.
[grid@Linux-01 ~]$ crsctl get css disktimeout
CRS-4678: Successful get disktimeout 200 for Cluster Synchronization Services.
Eviction occurs when cssd detects a heart beat problem i.e when it lost communication with other node or lost heart beat info from other node, CSS initiate node eviction.
Node eviction is used for i/o fencing the node, so the users doing i/o wont be able to access the malfunctioned system. I.e to avoid split brain syndrom.
In node eviction the node will be rebooted automatically and it will try to connect to the cluster.
From 12c onwards:
- If the sub-clusters are of the different sizes, the functionality is same as earlier the bigger one survives and the the smaller one is evicted.
- If the sub-clusters have unequal node weights, the sub-cluster having the higher weight survives so that, in a 2-node cluster, the node with the lowest node number might be evicted if it has a lower weight.
- If the sub-clusters have equal node weights, the sub-cluster with the lowest numbered node in it survives so that, in a 2-node cluster, the node with the lowest node number will survive.
52. What is rebootless node fencing?
Prior to 11.2.0.2 , If failures happens with RAC components like private interconnect and voting disk accessibility, then to avoid split brain , oracle clusterware does fast reboot of the node But the problem was that node reboot that, if any non cluster related processes are running are running on node, then those also gets aborted. Also , with reboot, the resources also need to be remasterd, which is expensive sometime.
Also if sometime if some issue or blockages in the i/o temporarily then also clusterware will misjudge that, initiate reboot.
So to avoid this, from 11.2.0.2 onward, this method has been improved, and known as reboot-less node fencing.
- First clusterware finds which node to be evicted
- Then i/0 generating processes will be killed on the problematic node.
- Clusterware resources will be stopped on the problematic node
- OHASD process would be running, will try continuously to start CRS, till issue is resolved.
But if due to any issue, the it is unable to stop the processes on the problematics node( i.e rebootless fencing fails) , then fast reboot will be initiated by cssd.
53. In case of node eviction due to private interconnect in a 2 node/3 node rac , How oracle decides which node to be evicted?
3 NODE RAC:
Let’s say there are nodes are A, B , C. If network heart beat of node A failed. Node B and Node C wont be able to ping to node A , But B and C can communicate between each other. So B and C will have 2 votes( one more self ping and other for ping to other node).
But A will have only one vote( i.e for the self ping). So A has less vote, oracle decides that A needs to evicted.
2 NODE RAC:
Lets say the nodes are A, B. If network heartbeat fails, then A and B wont be able to ping each other. So both A , B will have one vote each. So which node to be evicted?? Here quorm disk comes into play. This quorom disk(voting disk) also represents one vote. So both A and B will try to acquire that vote. Whoever acquire that quorom, gets 2 votes and stay in the cluster and other one gets evicted.
54. How can we improve global cache performance?
- We can increase the number of LMS processes, by increasing gc_server_process.
- We can set “_high_priority_processes”=”LMS*|LGWR*”
55. What is gc block lost?
It indicates issue with interconnect. If a requested block is not received by the instance in 0.5 seconds, the block is considered to be lost.
56. What is MTU ? How much MTU is recommended in oracle RAC?
MTU – Means maximum transmission unit.
Usually the standard is 1500 bytes . But the database block is 8k . So during block transfer between nodes, one block cannot be transfered at a time, It gets broken into pieces and these small packets are transfer.
So Oracle recommends to use 9000 byte MTU.
57. Suppose you have only one voting disk. i.e the diskgroup on which voting disk resides is in external redundancy. And if that voting disk is corrupted. What will be your action plan?
58. Where the OLR is stored? When olr backup is created.
By default, OLR is located at Grid_home/cdata/host_name.olr
The OLR is backed up after an installation or an upgrade. After that time, you can only manually back up the OLR. Automatic backups are not supported for the OLR.
59. Explain the backup frequency of OCR.
OCR backup is created at every four hours automatically.
ocrconfig -showbackup - > command to take manual ocr backup.
60. Why we need odd number of voting disks in RAC?

A node must be able to access strictly more than half of the voting disks at any time. So if you want to be able to tolerate a failure of n voting disks, you must have at least 2n+1 configured. (n=1 means 3 voting disks).
So whether you have 3 disks or 4 disks. only failure of 1 disks will be tolerated
61. How can i get the cluster name in RAC?
olsnodes -c
62. What is disktimeout and miscount ?
Miscount is the maximum delay in network heartbeat. By default miscount is set to 30 second . If the nodes are unable to communicate with each other through private interconnect for 30 seconds( miscount value), then node eviction will be initiated.
Disktimeout: It is the maximum voting disk heartbeat delay. Default is 200 seconds. If the CSSD is unable to write more than half of voting disks, then eviction will happen.
63. If olr file is missing ,How can you restore olr file from backup
# crsctl stop crs -f
# touch $GRID_HOME/cdata/<node>.olr
# chown root:oinstall $GRID_HOME/cdata/<node>.olr
# ocrconfig -local -restore $GRID_HOME/cdata/<node>/backup_<date>_<num>.olr
# crsctl start crs
64. Someone deleted the olr file by mistake and currently no backups are available . What will be the impact and how can you fix it?
If OLR is missing , then if the cluster is already running, then cluster will run fine. But if you try to restart it , It will fail.
So you need to do below activities.
On the failed node:
# $GRID_HOME/crs/install/rootcrs.pl -deconfig -force
# $GRID_HOME/root.sh
65. Explain the steps for node addition in oracle rac.
- Run gridsetup.sh from any of the existing nodes and select for add node option and then proceed with the rest of part.
- Now extend the oracle_home to the new node using addnode.sh script( from existing node)
- Now run dbca from the existing node and add the new instance.
Follow this below link for step by step details.
How to add a node in oracle RAC
66. Explain the steps for node deletion.
- Delete the instance usind dbca
- Deinstall ORACLE_HOME from $ORACLE_HOME/deinstall
- Run gridsetup.sh and select delete node option
Follow the below link for step by step details:
How to delete a node in oracle RAC
67. asm spfile location is missing inside gpnp profile, Then how will asm instance startup?
For this, we need to understand the search order of asm spfile
- First it will check for asm spfile location inside gpnp profile
- If no entry is found inside gpnp profile, then it will check the default path $ORACLE_HOME/dbs/spfile+ASM.ora or a pfile.
68. How you find out issue with private interconnect?
You can use traceroute to check if any issue with data transfer in private interconnect.
69. How to apply patch manually in RAC?
First do you the patch conflict check against the OH.
Then rootcrs.sh -prepatch to unlock the crs ( without unlocking the crs, opatch utility cannot do any modification to the grid home)
Then opatch apply ( to apply the patch)
Then rootcr.sh -postpatch to lock the crs
70.Lets say, you applied patch on node 2, and ran rootcrs.sh -post , and now it shows patch mismatch. But when you checked the oracle inventory(opatch lsinventory), Patches are same across both the nodes. Then what you will do?
In this case, you can run kfod command to find the missing patch.
Action plan:
Run kfod op=PATCHES on all the nodes and see on which nodes if any patch is missing.
Lets say you found that patch 45372828 is missing on node 2, then
On node2 as a root user , run below command
root#$GRID_HOME/bin/patchgen commit 45372828
After that you can run below commands to verify whether patch level is same or not .
kfod op=PATCHLVL
kfod op=PATCHES
After the confirmation , you can run rootcrs.sh -patch
71.How you troubleshoot, if the cluster node gets rebooted.
72.In a 12c two node RAC, What will happen, if I unplug the network cable for private interconnect?
Rebootless node fencing will happen. i.e the node which is going to be evicted, on that node all cluster services will be down. and the services will be moved to the surviving node. And crs will do the restart attempt continuously until the private interconnect issues fixed. Please note – the node will not be reboot, only the cluster services willl go down.
However Prior to 11.2 , In this situation, the node reboot will occur.
73.In a rac system , What will happen if i kill the pmon process?
The pmon will be restarted automatically.
74. Can we see DRM( Dynamic Resource Mastering) related information in oracle RAC?
Yes we can see DRM related data in gv$gcspfmaster_info by passing the object_id.
75. What is Grid infrastructure Management Repository(GIMR)?
Grid Infrastructure Management Repository (GIMR) is a centralised infrastructure database for diagnostic and performance data and resides in Oracle GI Home. It is a single instance CDB with a single PDB and includes partitioning (for data lifecycle management).
76. What is Rapid Home Provisioning?
77. If MGMTDB is not coming up for any reason, then what will be the impact on the existing databases?
No impact on existing database, it will just give warning.
78. What is the maximum number of voting disks we can configure?
We can configure upto 15 voting disk.( from 11g onward)
79. What is node weightage?
Prior to 12cR2 , during node eviction, node with lower number ( i.e which node joined the cluster first) survives .
But in 12cR2, node weightage concept has been introduced. I.e the node having more number of services or workload will survive the eviction.
There is another option to assign weightage to the services/databases using -css_critical=yes in srvctl database/service .
80. OCR file has been corrupted, there is no valid backup of OCR. What will be the action plan?
In this case , we need to deconfig and reconfig.
deconfig can be done using rootcrs.sh -deconfig option
and reconfig can be done using gridsetup.sh script.
80. Suppose someone has changed the permission of files inside grid_home. How you will fix it?
You can run rootcr.sh -init command to revert the permission.
# cd <GRID_HOME>/crs/install/
# ./rootcrs.sh -init
Alternatively you can check the below files under $GRID_HOME>/crs/utl/<hostname>/
– crsconfig_dirs which has all directories listed in <GRID_HOME> and their permissions
– crsconfig_fileperms which has list of files and their permissions and locations in <GRID_HOME>.
81. Can i have 7 voting disks in a 3 node RAC? Let’s say in your grid setup currently only 3 voting disks are present. How can we make it 7?
82. I have a 3 node RAC. where node 1 is master node. If node 1 is crashed. Then out of node2 and node3 , which node will become master?
83. Is dynamic remastering good or bad?
84. What will happen if I kill the crs process in oracle rac node?
85. What will happen if I kill the ohasd process in oracle rac node?
86. What will happen if I kill the database archiver process in oracle rac node?
It will be restarted.
87. What is application continuity and transactional dataguard in oracle rac?
88. What is this recovery buddy feature in oracle 19c?
Usually when instance is crashed in RAC, then one node is elected among the surviving nodes, for doing the recovery. And that elected node will read the redo logs of the crashed instance and do the recovery.
However in 19c, One instance will recovery buddy of another instance. like.
Instance A is recovery buddy of instance B.
Instance B is recovery buddy of instance C.
Instance C is recovery buddy of instance A.
And this buddy instance will the track the block/redo changes of the mapped instance and keep them in its sga( in hash table ).
So recovery buddy features helps in reducing the recovery time( as it eliminates the elect and redo read phase).
89. What is nodeapps?
Nodeapps are standard set of oracle application services which are started automatically for RAC.
Node apps Include: vip,network,adminhelper,ONS
90. CSSD is not coming up ? What you will check and where you will check.
- Voting disk is not accessible
- Issue with private interconnect
2.the auto_start parameter is set to NEVER in ora.ocssd resource . ( To fix the issue, change it to always using crsctl modify resource )
91. How you check the cluster status?
crsctl stat res -t
crsctl check crs
crsctl stat res -t -init
92. crsctl stat res -t -init command, what output it will give?
93. What are the different types of heart beats in Oracle RAC?
There are two types of heart beat.
Network heartbeat is across the interconnect, every one second, a thread (sending) of CSSD sends a network tcp heartbeat to itself and all other nodes, another thread (receiving) of CSSD receives the heartbeat. If the network packets are dropped or has error, the error correction mechanism on tcp would re-transmit the package, Oracle does not re-transmit in this case. In the CSSD log, you will see a WARNING message about missing of heartbeat if a node does not receive a heartbeat from another node for 15 seconds (50% of misscount). Another warning is reported in CSSD log if the same node is missing for 22 seconds (75% of misscount) and similarly at 90% of misscount and when the heartbeat is missing for a period of 100% of the misscount (i.e. 30 seconds by default), the node is evicted.
Disk heartbeat is between the cluster nodes and the voting disk. CSSD process in each RAC node maintains a heart beat in a block of size 1 OS block in a specific offset by read/write system calls (pread/pwrite), in the voting disk. In addition to maintaining its own disk block, CSSD processes also monitors the disk blocks maintained by the CSSD processes running in other cluster nodes. The written block has a header area with the node name and a counter which is incremented with every next beat (pwrite) from the other nodes. Disk heart beat is maintained in the voting disk by the CSSD processes and If a node has not written a disk heartbeat within the I/O timeout, the node is declared dead. Nodes that are of an unknown state, i.e. cannot be definitively said to be dead, and are not in the group of nodes designated to survive, are evicted, i.e. the node’s kill block is updated to indicate that it has been evicted.
Reference – https://databaseinternalmechanism.com/oracle-rac/network-disk-heartbeats/
[grid@Linux-01 ~]$ crsctl get css misscount
CRS-4678: Successful get misscount 30 for Cluster Synchronization Services.
[grid@Linux-01 ~]$ crsctl get css disktimeout
CRS-4678: Successful get disktimeout 200 for Cluster Synchronization Services.
94. What is preferred and available in a service in RAC?
95. Suppose I am running a insert statement by connecting to a database using service . And if that instance is crashed, then what will happen to the insert statement?
96. can there be gc-4-way wait events in 4 node rac?
97. suppose in a 5 node rac, i ran srvctl stop database -d <TESTDB>, then how this information will be conveyed to other nodes? Provide the sequence of steps it will happen after this step.
96. Can there be multiple consistent read blocks ?