
1. Difference between local partitioned index and global partitioned index
In local partitioned Index, there is one to one relation between data partition and index partition. i.e for each table partition, there will be on respective index partition( based on the same partitioned key on table) .
But in global partitioned Index, there is no one to one relation. i.e a table can have 20 partitions and the global partitioned Index can have 4 partitions. Also the “highvalue=MAXVALUE” is mandatory for creating global index.
2. What is prefixed and non-prefixed partitioned Index.
If the index column same as the partition key or the left most column of the partition keys , Then we call it prefix. If the indexed column is either not the leading edge of the partitioned keys or not a part a partitioned key, then we can call it non-prefixed.
Prefixed Indexes will use partition pruning , But non-prefixed partitioned index will not use partition pruning.
For global partitioned Index, there is only prefixed index. Oracle doesn’t support non prefixed global partitioned index.
3. Can we create a unique local partition index?
Yes we can create a unique local partition index But it can be created only on a partition key column( or a subset of key column)
4. What is a partial Index? What are the advantages?
From 12c onwards, Index can be created on a subset of partitions. This can be used, when we know about which partitioned are widely used , which are hardly used. This will save in saving storage space.
5. What is a b tree index and where it is used?
6. What is a BITMAP index tree and in which scenario this index is used?
7. When we should do index rebuild? What happens when we do index rebuild?
8. What is IOT( Index Organised Table)? When we should use this?
Primary key is a must in IOT table.
an index-organized table is most effective when the primary key constitutes a large part of the table’s columns. Also when the table data is mostly static.
9. How to rebuild an INDEX?
There are two ways to rebuild an index.
OFFLINE:(During this the exclusive lock will be applied on the table, which will impact DDL and DMLS.)
ALTER INDEX SCHEMA_NAME.INDEX_NAME REBUILD;
Alternatively we can drop and recreate the index .
ONLINE:(DML and DDLS operations will work as usual, without any impact).
ALTER INDEX SCHEMA_NAME.INDEX_NAME REBUILD ONLINE;
10. How can we improve the speed of index creation on large table?
First we can use parallel in the creation index syntax to improve the speed. However make sure to revert the parallelism to default once index is created.
create index TEST_INDX_object on test(object_name) parallel 12;
alter index TEST_INDX_object noparallel;
Apart from this we can add nologging parameter in create index statment.
Create index , generates a lot of redo and these logs are of no use. So we can create the create the index with nologgin as below.
create index TEST_INDX_object on test(object_name) nologging parallel 12;
11. What is clustering factor?
Clustering factor , indicates the relation between table order and index order. In index the the key values are stored in ordered fashion, But in the table, there rows are stored in the order of insert .
low CLUSTERING_FACTOR means, data is in ordered manner in table. I.e we can say it is good clustering factor. The minimum clustering_factor is equal to number of block of the table.
High CLUSTERING_FACTOR means data is randomly distributed. i.e bad clustering factor. Maximum clustering factor is equal to number of rows of a table.
Please note – rebuilding index, will not improve the clustering factor. You need to recreat the table to fix this.
QUERY TO FIND – > SELECT INDEX_NAME,CLUSTERING_FACTOR FROM DBA_INDEXES;
11. How oracle calculates clustering factor of an index?
These diagrams will help you in understanding how clustering factor is calculated.
For calculating CF, Oracle will fully scan the index leaf blocks. These leaf blocks contain rowid, So from rowid, it can find the block details of the table. So while scanning the index, whenever is a change in block id, it will increment the CF by one.
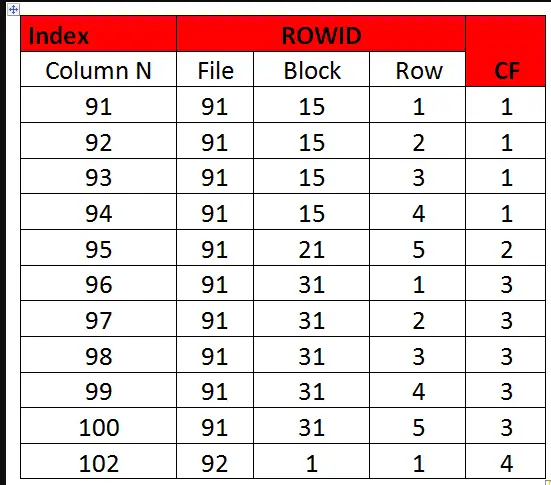
GOOD clustering factor:
In the below diagram, for the first 4 rows, the block is 15 , so CF is 1 at that time. But the fifth row is in different block, so CF incremented by 1 . So similarly with every block change, the CF will be incremented by one.
Bad clustering factor:
In the below diagram, for the rows, the block id is getting changed very frequently. So CF is very high. Which is bad.
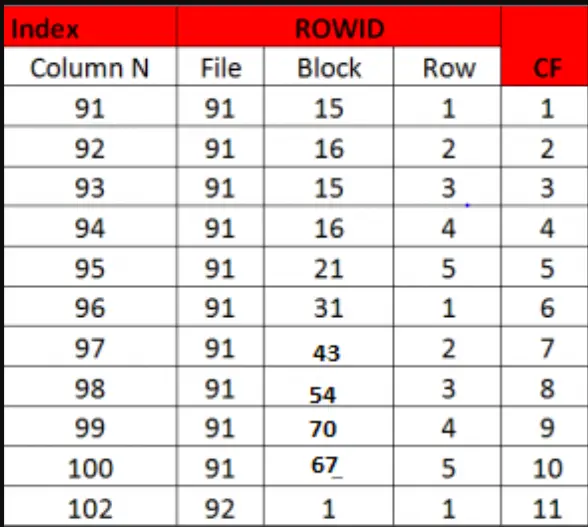
Diagram reference – https://techgoeasy.com/clustering-factor/
12. What is rowid ?
Rowid is pseudocolumn, which contains below information.ROWID is used to get the exact location of a row in the database.It is the fasterst way to locating a row.
When we create index, the rowids and the column_values are stored in the leaf block of the index.
- object_id
- block number
- position of the row in the block
- datafile number in which the row resides.(i.e relative file number)
13. What data is stored in the index leaf block?
Index leaf block stores the indexed column values and its corresponding rowid( which is used to locate the actual row).
14. How oracle uses index to retrieve data?
When query hits the database, The optimizer creates an execution plan involving the index. Then the index is used to retrieve the rowid. And using the rowid, the row is located in the datafile and block.
15. Explain the scenario where , the data will be retrieved using only index ,without accessing the table at all?
In case of covering index, i.e when we are only retrieving the indexed column data.
16. What is a covering index?
Covering index mean, when the query is trying to fetch only indexed column data, then we call it covering index. Because, in this case, the access to table is not required, as the all the column data is already inside index.
select emp_id,emp_name from emp_list where emp_name=’RAJU’;
Here index is already presen ton emp_id,emp_name;
17. What is cardinality in oracle?
Cardinality refers to the uniqueness of the data in a particular column of a table. If the table column has more number of distinct values, then cardinality is high. If distinct values are less, then cardinality is low.
18. Why my query is doing full table scan , despite having index on the predicate.
With below scenarios the optimizer might not use the index.
- condition where index_column like ‘%id’
- Huge data is requested from the table.
- Very high degree of paralleism is defined in table.
- Very high degree of paralleism is defined in table.
- Also when we search for a null value.
19. Difference between invisible index and unusable index?
When we make the index invisible, optimiser will not use it . But the index will be maintained by oracle internally.i.e for all dml activites on table, the index will be updated. If we want the optimizer to use it , we can make it visible using alter table command.
But when we make the index unusable, then oracle optimiser will not use it and also the the index will not be maintained bz oracle further. So we want to use the index again then, we need to rebuild again. This is usually used in large environments to drop index. Because in large database, dropping index may take a lot time. So First it can be made unusable for some time and during low business hours, index can dropped.
20. Why moving a table , makes the index unusable?Do you know any other scenarios which will make the index unusable?
When we move the table , the rows moved to a different location and gets a new rowid. But Index still points to the old rowids. So we need to rebuild the index, which will make the index entries to use new set of rowids for the table row.
Different reasons for index unusable is dropping table partition/truncate partition.
21. Do you know any scenario where making the index unusable can be helpful?
In DWH envs, when huge data loading operations are performed on tables having lot of index, the performance will slow down, as all the respective indexes need to be updated . So to avoid this, we can make the indexes unusable and load the data. And once loading is completed, we can recreate/rebuild the indexes.
21. Difference between primary key and unique key?
Unique key constraint can contain null value, But primary key constraints should be not null .
22. How index works on query with null value? Lets say i am running a query select * from emp where dept_Name=null; and an index is present on dept_name . In that case, will oracle use the index?
First we need to find, what type of index it is using. If the index is B-Tree then null values are not stored in the b-tree index. So it will do a TABLE FULL SCAN.
But if the index is a BITMAP index, then for null values also index will be used ( i.e it will do index scan), Because bitmap index stores null value also.
23. Between b-tree index and bitmap index, which index creation is faster?
Bitmap index creation is faster.
24. Can I create a bitmap index on partitioned table?
Bitmap index can be created on partitioned table, but they must be local partitioned index.
25. Can I create two indexes on a same column in oracle?
Prior to 12c, it was not allowed to have two indexes on same column. However from 12c onwards , we can create two indexes on same column, but the index_type should be different. i.e if i have already btree index on a column, then other index should be a bitmap.
26. What is the difference between heap organized table and index organized table?
27. What is an overflow in IOT table? Explain its purpose.
28. Can we create a secondary index on IOT?
Yes we can create an secondary index( Either b-tree or bitmap _) IOT.
29. Is it possible to convert a heap organized table to index organized table and vice versa?
30. In which scenarios i should IOT ?
Mostly for a table with small number of columns and most of the columns are in primary key and mostly accessed.
Also used where requirement is for fast data access of primary key column data.
It is not recommended in DWH ,because it involve bulk data loading, which will make the physical guess to stale very quickly.
31. When should i rebuild an IOT index?Explain different ways to do it.
32. We want to find the list of unused index in a database. How can I do that?
We can alter the index with MONITORING USAGE clause. After the respective index usage will be tracked.
33. Explain difference between coalescing and shrinking in reducing index fragmentation?
Coalescing combines adjacent leaf blocks into a single block and put the new free leaf blocks in the free list of index segment,Which can be used by index in future. But it will not release the free space to database.
But shrinking will release the free space to database
34. What are the different index scanning methods ?
INDEX UNIQUE SCAN:
INDEX RANGE SCAN:
INDEX FULL SCAN:
INDEX FAST FULL SCAN:
INDEX SKIP SCAN:
35. Which index scan method cause , db file scattered read wait event( Ideally indexes cause db file sequential read).
Index fast full scan cause db file scattered read wait event. Because this method used multi block read operations to read the index. This type of operations run in parallel.
36. If i use not equal condition in the where clause, will it pick the index? like select * from table_tst where object_id <> 100?
If this query returns high number of rows, then optimizer will use FULL TABLE SCAN i.e index will not be used.
And if you try to force the query to use index using index hint, then also it will do INDEX FULL SCAN, but not Index range scan.
37. If i query with wild character in where clause, Will the optimizer pick index?
It depend where the wild character is placed.
If query is like select * from emp where emp_name like ‘SCO%’; ->> Then it will use index
And
If query is like select * from emp where emp_name like ‘%SCO’; –> This will not use Index
38. What is a functional Index?
If the query contains function on a index column in the where then normal index will not be used.
i.e query like select * from emp where lower(emp_name)=’VIKRAM’; — Then optimizer will not use normal index.
So in this case, We can create a function index as below , which will be used by optimizer.
create index fun_idx on emp(lower(emp_name));
39. what are the index related initialization paramters.
optimizer_index_caching
optimizer_index_cost_adj
39. If given an option between index rebuild and Coalsace, which one you should choose?
Coalasce is always prefered over index rebuild,
Because, index rebuild need twice the size to complete the activity. Also it will generate lot of redo during the activity and there might be impact on CPU usage.
39. Should we do index rebuild regularly?
It is advised not to do index rebuild regularly or not at all ( unless performance assessment finds issue with index).
The general believe that index rebuild balances the index tree, and improves clustering factor and to reuse deleted leaf blocks.But this is myth. Because Index is always balanced and the rebuilding index doesn’t improve clustering factor.
39. Does rebuild index helps in clustering factor?
Rebuilding an index never has an influence on the clustering factor but instead requires a table re-organization.
39. What is index block splitting? Different types of splitting?
Index entries are managed in a orderly fashion in index structure. So if a new key is getting added, and there no free space of the key, then index block will be splitted.
Two types of splitting.
- 50-50 Splitting – > To accomodate the new key, The new block will be created, 50 percent will be stored in the existing leaf block and 50 percent will be in the new block.
- 90-10 splitting – > If the index entry is the right most value( when index entry is sequentially increasing like transaction_date), then leaf block will be splitted and the new index key will added to the new leaf block
HISTOGRAM and STATISTICS
1. What are statistics in oracle? What type of data in stores?
2. Difference between statistics and histogram?
3. What is a histogram ? What are different types of histogram?
Histogram , we can say a type of column statistics which provides more information about data distribution in table column.
Pre-12c , there were only 2 types of histogram.
Height based,
Frequency based
From 12c , another two types of histograms were introduced, apart from above two.
Top N frequency
Hybrid
5. What is the need of histogram?
By default oracle optimizer thinks that data is distributed uniformly. And accordingly it calculates the cardinality.
But if the data is non-uniform, i.e skewed, then the cardinality estimate will be wrong. So here histograms comes into picture. It helps in calculating the correct cardinality of the filter or predicate columns .
-- When no histograms are present:
SQL> select column_name,num_distinct,num_buckets,histogram,density from dba_tab_col_statistics where table_name='HIST_TEST';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM DENSITY
----------------------- ------------ ----------- --------------- ----------
OBJECT_NAME 107648 1 NONE 9.2895E-06
OWNER 120 1 NONE .008333333
OBJECT_TYPE 48 1 NONE .020833333
OBJECT_ID 184485 1 NONE 5.4205E-06
SQL> SELect count(*) from hist_test where object_type='TABLE';
COUNT(*)
----------
17933
Execution Plan
----------------------------------------------------------
Plan hash value: 3640793332
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 9 | | |
|* 2 | INDEX RANGE SCAN| TEST_IDX2 | 3843 | 34587 | 1 (0)| 00:00:01 | --- optimizer estimates incorrect number of rows.
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_TYPE"='TABLE')
--- Gather stats again:
SQL>
SQL> BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
ownname => 'SYS',
tabname => 'HIST_TEST',
cascade => true, ---- For collecting stats for respective indexes
granularity => 'ALL',
estimate_percent =>dbms_stats.auto_sample_size,
degree => 8);
END;
/ 2 3 4 5 6 7 8 9 10
PL/SQL procedure successfully completed.
SQL> SELect count(*) from hist_test where object_type='TABLE';
COUNT(*)
----------
17933
Execution Plan
----------------------------------------------------------
Plan hash value: 3640793332
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 9 | | |
|* 2 | INDEX RANGE SCAN| TEST_IDX2 | 17933 | 157K| 1 (0)| 00:00:01 | --- Optimizer using the exact nuumber of rows.
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_TYPE"='TABLE')
SQL> select column_name,num_distinct,num_buckets,histogram,density from dba_tab_col_statistics where table_name='HIST_TEST';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM DENSITY
----------------------- ------------ ----------- --------------- ----------
OBJECT_NAME 107648 1 NONE 9.2895E-06
OWNER 120 1 NONE .008333333
OBJECT_TYPE 48 48 FREQUENCY 2.7102E-06 --- Frequency histogram is present
OBJECT_ID 184485 1 NONE 5.4205E-06
6. What changes to histogram are introduced in 12c version . And Can you explain some problems with 11g histogram?
In 12c two new histograms has been introduced. TOP N frequency and Hybrid.
7. Explain how oracle decides which histogram to create?
NDV -> Number of distinct values
n – > number of buckets.
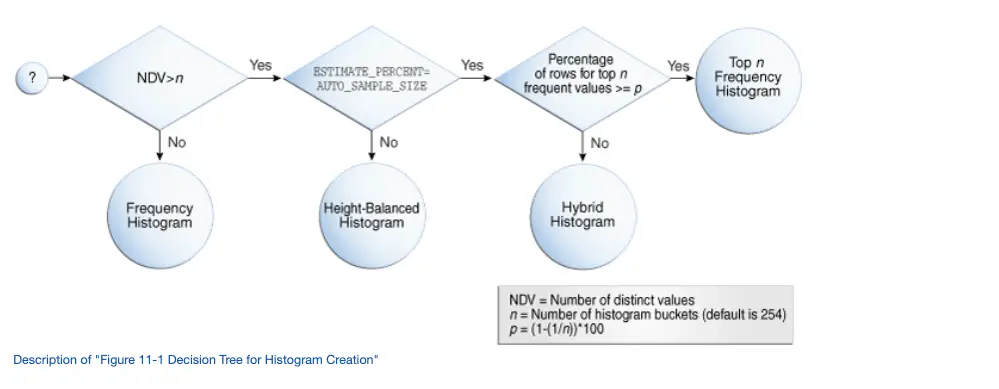
8. When oracle creates histogram?
When we run gather stats command with method_opt set AUTO, It will check the sys.col_usage$ , table to see, whether the columns of the table used as join or predicate ( ie. in where clause or join). And if columns are present, then oracle will create histograms for the column ( Only for the columns having skewed data).
ie. if a column has not used in join or where clause of any query, Then even if we run gather stats, the histogram will not be created.
Lets see the demo:
--- HISTO_TAB is a new table. SQL> select column_name,num_distinct,num_buckets,histogram,density from dba_tab_col_statistics where table_name='HISTO_TAB'; no rows selected -- Run status: SQL> SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS ( ownname => 'SYS', tabname => 'HISTO_TAB', cascade => true, ---- For collecting stats for respective indexes granularity => 'ALL', estimate_percent =>dbms_stats.auto_sample_size, degree => 8); END; / 2 3 4 5 6 7 8 9 10 PL/SQL procedure successfully completed. SQL> SQL> SQL> select column_name,num_distinct,num_buckets,histogram,density from dba_tab_col_statistics where table_name='HISTO_TAB'; COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM DENSITY ----------------------- ------------ ----------- --------------- ---------- LN_NUM 9398 254 NONE .000034 LN_NUM2 137 1 NONE .00729927 MODIFICATION_NUM 478 1 NONE .00209205 ORDER_ID 637056 1 NONE 1.5697E-06 -- Now run a query with a column as predicate. SQL> select count(*) from HISTO_TAB where ln_Num=1; COUNT(*) ---------- 625700 SQL> select dbms_stats.report_col_usage(OWNNAME=>'SYS',TABNAME=>'HISTO_TAB') from dual; DBMS_STATS.REPORT_COL_USAGE(OWNNAME=>'SYS',TABNAME=>'HISTO_TAB') -------------------------------------------------------------------------------- LEGEND: ....... EQ : Used in single table EQuality predicate RANGE : Used in single table RANGE predicate LIKE : Used in single table LIKE predicate NULL : Used in single table is (not) NULL predicate EQ_JOIN : Used in EQuality JOIN predicate NONEQ_JOIN : Used in NON EQuality JOIN predicate FILTER : Used in single table FILTER predicate JOIN : Used in JOIN predicate GROUP_BY : Used in GROUP BY expression ............................................................................... ############################################################################### COLUMN USAGE REPORT FOR SYS.HISTO_TAB ..................................... 1. LN_NUM : EQ --- >> ############################################################################### -- Run stats again: SQL> SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS ( ownname => 'SYS', tabname => 'HISTO_TAB', cascade => true, ---- For collecting stats for respective indexes granularity => 'ALL', estimate_percent =>dbms_stats.auto_sample_size, degree => 8); END; / 2 3 4 5 6 7 8 9 10 PL/SQL procedure successfully completed. SQL> SQL> select column_name,num_distinct,num_buckets,histogram,density from dba_tab_col_statistics where table_name='HISTO_TAB'; COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM DENSITY ----------------------- ------------ ----------- --------------- ---------- LN_NUM 9398 254 HYBRID .000034. --- >> THIS ONE LN_NUM2 137 1 NONE .00729927 MODIFICATION_NUM 478 1 NONE .00209205 ORDER_ID 637056 1 NONE 1.5697E-06 SQL> SQL> 64. What is the significance of method_opt parameter in gather stats command. ?
Method_opts parameter of dbms_stats procedure controls below things.
1. Creation of histogram .
2. Creation of extended statistics
3. On which columns base statistics will be gathered.
Syntax – >
FOR ALL [INDEX|HIDDEN] COLUMN SIZE [SIZE_CLAUSE]
First part( Controls collection of base statistics for columns)
FOR ALL COLUMNS – Gathers base statistics for all columns
FOR ALL INDEXED COLUMNS – Gathers base statistics for columns included in index
FOR ALL HIDDEN COLUMNS – Gathers base statistics for virtual columns
2nd part ( size parameter controls the creation of histogram)
In size_clause we defines the number of buckets. Maximum is 254 Buckets.
Auto means – > oracle will create histogram automatically as per usage in col_usage$ table.
If we say method_opt => ‘ for all columns size 1’ : It means base statistics will be collected for all columns , and as bucket size is 1, so Histogram will not be created.
9. What are extended statistics and expression statistics?
10. How statistics become stale?
By default stale_percent preference is set to 10 %. So when 10 percent of rows gets changed , then the statistics will become stale.
11. Is there any way we can configure the database ,that the statistics will never go stale( Despite having thousands of transactions).
From 19c onwards it is possible. 19c introduced real time statistics, Mean for the DML activities , the statistics data will be collected in real time ( So stale stats will never occur).
This feature is controlled by OPTIMIZER_REAL_TIME_STATISTICS parameter(True/False).
12. For large schemas, gather stats can take a lot of time. How can we speed up of the gather statistics process?
We can use Degree parameter to create multiple parallel threads to increase the speed. Other option is concurrent statistics gathering. i.e if we set the preference parameter CONCURRENT , then statistic will be gathered for multiple tables of a schema, at a same time.( by creating multiple scheduler jobs).
We can combine both the option to speed up .(But make sure these can increase the load on the system).
GENERIC:
1. What is an ITL?
2. Lets say a user want to update 50 rows in a table( i.e a block) , then how many ITL slots are required?
We need one ITL slot for one transaction. i.e ITL slots are not allocated as per row. It is as per transaction id. Each slot is for one transaction id.
34. What is a dead lock in oracle?
Dead block occurs when session A holding resource requested by session B , And at the same time Session B also holding a resource requested by session A.
This error occurs usually due to bad application design.
34. What will be the impact, if run compile a package/procedure during peak business hour?
34. A database has SGA of 20G and a user ran a select query on a big table, whose size is of 100 GB, will the user get the data?
34. What is the significance of DB_FILE_MULTIBLOCK_READ_COUNT?
This paramter specifies, how many block will be fetched with each i/o operation. It allows the full scan operations to complete faster.
34. What is db time and elapsed time in AWR?
34. I ran one insert statement on a session but didn’t commited it. Then i ran one DDL statement( alter table statement) on the same session. Once alter is done, I have closed the session. So now what will happen to the insert transaction?
DDL statements cause implicit commit. So the insert statement will be commited , when we ran the DDL statement.
34. As we know that awr reports only few top sql queries. But I have a requirement that, a specific sql query should be reported in the awr report, whether it is a top sql or not. Can we do that.
Yes we can do this. We need to get the sql_id of the sql query and mark it as coloured using dbms_workload_repository package.
34. Dynamic sampling?
34. What are the different levels of sql trace?
10046 – sql trace
10053 – optimizer trace
34. What is this parameter optimizer_mode?
ALL_ROWS
FIRST_ROWS
FIRST_ROWS n(1,10,100) – .
34. Is it true that , parallel query scan use direct path read bypassing the buffer cache?
Yes parallel scans are direct path read , they by passes the data buffer.So they dont have to worry about catering blocks from buffer cache.
But what is there is dirty buffer in buffer cache, which is not written to disk. And if direct read is happens from disk, then parallel query will give wrong results. So to fix this, parallel query will first issue a segment checkpoint, so that dbwr will write all the dirty buffers of that segment to disk.
Note that – with parallel scan as direct path read happens, db_file_multi_block_read_count paralmeter will be optimally used.
34. Difference between freelist management and automatic segment space management(ASSM)?
35. What is direct path read?
In Direct Path Read, the server process reads the data block from disk directly into process-private memory i.e. PGA bypassing the SGA.
Direct read happens during below activities.
- Reads from a temporary tablespace.
- Parallel queries.
- Reads from a LOB segment.
36. What is bind ? How to use of binds helps ?
Bind variable is a place holder in a sql statement, which can be placed with any valid value. Usually application triggers queries with bind variables and the these bind values are passed at run time.
select * from emp_name where emp_id=:1
Advantages is – Binds allow sharing the parent cursors in library cache. i.e it helps in avoiding hard parsing.
37. What is bind peeking? What is the problem with bind peeking? What oracle did to fix this issue?
The problem with bind was that, the query optimizer doesn’t know the literal values. So especially when we use range predicates like < and > or between, the optimizer plan might varry when liternal values passed in the where clause( i.e full table scan or use of index). So optimizer might give wrong estimates when using binds.
So to overcome this, In oracle 9i bind peeking concept was introduced.( As per dictionary , peeking means to have a glance quickly.) With this, before execution plan is prepared, the optimizer will peek into the literal values and use that to prepare the execution plan. So now as the optimizer is aware of the literal values, it can produce a good execution plan.
But the problem with bind peeking was that, the optimizer will peek into the literal values only with the first execution . And the subsequent query execution use same execution plan of the first one, despite these could have a better execution plan.
So to reduce this problem , In 11g, oracle introduced adaptive cursor sharing.
38. What is adaptive cursor sharing?
We can call it bind aware. With this feature, for every parsing the optimizer performs the estimation of selectivity of the predicate. Based on that right child cursor is used/shared.
Adapative cursor sharing is introduced in 11g oracle. Adaptive cursor sharing kicks in when the application query uses binds or when cursor_sharing is set FORCE.
39. What is the significance of cursor_sharing parameter? What is the default one?
Below are the 3 possible values of cursor_sharing parameter.
EXACT
FORCE
SIMILAR
40. Can i run sql tuning advisor on standby database?
Yes we can do using database_link_to parameter while creating tuning task.
The public database link need to created in primary with user sys$umf , pointing to primary db itself.
41. Can i get the sql_id of a query before it is being executed?
From 18c onwards you can set feedback only sql_id , in sql and run the query
SQL> set feedback only sql_id
SQL> select * from dba_raj.test where owner =’public’;
1 row selected.
SQL_ID: 11838osd6slfjh88
42. How can we improve the speed of dbms_redef operation?
You can run below alter parallel commands before starting the dbms_redef process.
ALTER SESSION FORCE PARALLEL DML PARALLEL 8;
ALTER SESSION FORCE PARALLEL QUERY PARALLEL 8;
43. How can i encrypt an existing table without downtime?
You can use the dbms_redef method to do this online.
44. What is the difference between PID and SPID in v$Process?
PID – > Oracle internal counter, which oracle use for its own purpose. For every new process, PID increments by 1.
SPID – > It is the operting system process. SPID is mostly used by DBAs for tracing or killing session.
45. Do you know where awr data is store?
It is stored in SYSAUX tablespace.
46. What are the different access methods in explain plan.

47. How many types of joins oracle has?
NESTED LOOP:
Nested loops joins are useful when small subsets . For every row in the first table (the outer table), Oracle accesses all the rows in the second table (the inner table) looking for a match.
HASH JOIN:
Hash joins are used for joining large data sets. The Optimizer uses the smaller of the two tables or data sources to build a hash table, based on the join key, in memory. It then scans the larger table and performs the same hashing algorithm on the join column(s). It then probes the previously built hash table for each value and if they match, it returns a row.
SORT MERGE JOIN:
Sort Merge joins are useful when the join condition between two tables is an in-equality condition such as, <, <=, >, or >=. Sort merge joins can perform better than nested loop joins for large data sets. The join consists of two steps:
REFERENCE – > https://sqlmaria.com/2021/02/02/explain-the-explain-plan-join-methods/
48. What is lost write in oracle?
49. Which checks are performed in parsing phase of a query?
SYNTAX CHECK: It checks whether syntax is correct or not
SEMANTIC CHECK: It checks whether the user has permisson to access the table or whether table and column name is correct or not.
SHARED POOL CHECK: It checks whether it should do soft parse or hard parse. To explain in detail. When ever a sql query comes, db calculates the hash value of that statement. and then it search that hash value in the shared pool ( esp shared sql area). If it is already present, then it will try to reuse the same execution plan. In that case we call it soft parse. If the hash value is not found or it cannnot reuse the existing plan, then hard parsing happens.
50. What are some of the os commands to monitor oracle server ?
TOP :
It provides information like load average, cpu , memory usage and processes consuming high cpu.
VMSTAT: Virtual Memory statistics : Details like cpu run queues, swap, disk operations per second. paging details and load information.
usage – > vmstat -5 10
vmstat -a ( to get active and inactive memory information)
SAR ( for linux):
System activity Report – > It can be used to gerenate cpu usage ( like system, user,idle) ,iowaits . Apart from that we can get the historical report from sar using command like
sar -u -s 06:30:00 -e 07:15:00
It is also recommended to install oswatcher on the servers. Using oswatcher collected file, we can generate different graphs for a particular duration.
51. What is ASH?
Every second, Active Session History polls the database to identify the active sessions and dumps relevant information about each of them. Session is deemed as active, if it is consuming cpu or waiting for non idle wait events.
We can view these information on gv$active_session_history. After a period, these data will be flushed to dba_hist_active_session_history.
52. Explain about ORA-1555 snapshot too old error. What is the action plan for this error?
53. Explain about ORA-4031, unable to allocate shared memory error?
WAIT EVENTS:
1. When log_file_sync wait event occurs?
When user session commit or rollback. when user commits, LGWR writes the contents of redo log buffer to online redolog files and once writing is done, it will post the same to user. So while user is waiting for the confirmation from LGWR, it will wait for for log file sync event.
If application is causing log of commits , then log_file_sync wait can be a top wait event in AWR.
This wait event can be reduced by checking with appication, whether they can reduce unnecessary commit and do commit in batches.
Slow i/o do redo disk can also cause this issue.
2. what you know about log_file_parallel_write wait event?
This wait event occurs when log buffer contents are getting written to redo log file. This might be the top event when application cause lot of commits or database is in hot backup mode. slow i/o to redo disk can also cause this.
One solution is to increase the log buffer size and reduce the number of commits. Also try avoiding putting the database in hot backup mode.
3. How can you fix log file switch(checkpoint incomplete) wait event?
To complete a checkpoint, dbwr must write every associated dirty buffer to disk and every datafile and controlfile should be updated to latest checkpoint number
Let’s say LGWR finished writing to log file 2 and ready to switch to log file 1 and start writing. However the DBWR is still writing checkpoint related redo information of logfile 1 to disk. So it cannot write to logfile 1 unless that checkpoint is completed ( i.e unless dbwr completed its writing)
To fix this. Increase the redo log size or add more number of log file.
4. log buffer space?
4. What are some buffer cache related wait events?
db file parallel read
db file sequential read
db file scattered read
free buffer wait
latch cache buffer chain
latch cache buffer lru chain
5. When db file scattered read wait event occurs?
We can call this multi block read. While doing full table scan or index fast scan, lot of blocks need to be fetched from disk to buffer and they will be in buffer in a scattered manner( Because these buffers in the buffer cache will not contagious) . And during this activity, it need to find lot of free buffer which leads to this wait event.
Solution:
Avoid full tablespace if possible.
If large tables, consider using partitioning.
Check whether proper indexing is in place to avoid full scan.
6. what is db file parallel read wait event??
7. what is db file sequential read wait event??
Sequential read means, single block read.This is largely due to index full scan or index scan with order by clause.
When rows in the table are in random order, then clustering factor will be very high. . i.e more table blocks need to be visited to get the row in index block.
Also when index blocks are fragmented, then more number of blocks need to be visited, which can cause this wait event.
9. redo allocation latch contention?
10. redo copy latch contention?
8. What is buffer busy wait? What should be the approach to fix it?
Buffer busy wait is due to excessive logical i/o.
This wait happens, when server process, got a latch on the hash bucket, But another session is holding the block in buffer( either it is writing to that block or may be buffer getting is flushed to disk).Some times this is known as read by other sessions.
To troubleshoot this issue, first we need to find out the the responsible object. We can get the p1(file_id),p2(block),p3 (reason) details of the query from v$session_wait . And by using the p1 and p2 values, we can get the segment details from the dba_extents.
Then we need to check , the segment is of which type.
If it is a undo – > Then need to increase the size of undo tablespace.
If it is data block – > Means the query might be inefficient . May be we need to try moving the hot blocks to a di
11. LATCH: CACHE BUFFER CHAINS (CBC) wait event?
Each buffer in the buffer cache has an associated element in the buffer header array.( These details are available in v$bh).
Buffer header array is allocated in shared pool. These buffer header arrays stores attribute and status details of the buffers. These buffer headers are chained together using double linked list.and linked to hash bucket. And there are multiple hash buckets and these buckets or chains are protected by latch cache buffer chain.
If a process want to search or modify a buffer chain , then first it need to get a latch i.e CBC latch.
So when multiple users want to access the same block or the other block on the same hash bucket, then there will be contention for getting a latch. So when contention is severe( i.e process is finding to difficult to get a latch) , then this LATCH : CBC wait event will occur.
Not only accessing the same block.,But when simultaneous insert, update runs on a same block , then cloned buffers copies also gets attached to same hash bucket and it increases the buffer chain length . So process after getting the latch, takes more time to scan through the long chain.
The wait event occurs when logical I/O is high. So to avoid this wait event, we need to find a way to reduce the logical I/O.
Solution:
The solution depends upon what query is causing the issues.
If the issue is due to no. of users accessing the same data set, then we can increase the PCTFREE of table/index., so that there will less rows per block. and the data will spread across multiple chains.
9. LATCH: CACHE BUFFER LRU CHAINS?
This wait event occurs when physical i/o is high.
When the requested block is not available in Buffer cache, then server process need to read the block from disk to buffer cache. For that it needs a free buffer. So for this , server process search through the LRU list, to get the free block. And search or access a LRU list , first it needs to get a Latch which is called LATCH – cache buffer lru chain.
Also when the dbwr writes the buffers to disk, first it scans through lru list to get the dirty buffer which need to flushed. For this purpose also it needs to get a latch.
Below are some of the activities which are responsible for this wait event.
Small buffer cache- Means , very frequently dirty blocks need to be writen to disk very often. which will increase the latch contention.
Very lot of full table scan – Means, it need to find lot of free buffer to read the the data from disk. Means very often latch need to obtained.
8. What is free buffer wait event?
Reasons:
- DBWR is unable to handle the load
- Buffer cache size is small
10. Why the wait event enq: TX – allocate ITL entry occurs and how to fix it.
Interested Transaction List(ITL) is a internal structure in each block. When a process want to change a data in block, it need to get a empty ITL slot to record that the transaction is interested in modifying the block. Once slots are over, it uses the free spaces available on block.. The no. of ITL slots are controlled by INITRANS . Default Value of INITRANS is 1 for table and 2 for table.
So concurrent DMLs happens on a block and There are no free ITL slots, then it wait for a free ITL slot, which cause this wait event.
To fix this we can increase the INITRANS value , if still issue present then increase the PCTFREE.
Steps to initrans.
ALTER TABLE INITRANS 60;
But problem is the new value is applicable for the new blocks. So to apply to changes to all the blocks, we need to move the table and rebuild respective indexes.
ALTER TABLE EMPLOYEE MOVE ONLINE;
ALTER INDEX EMP_ID REBUILD ONLINE;
If after updating initrans also issue is there , then update PCTFREE and move table and index.
ALTER TABLE EMPLOYEE PCTFREE 20;
ALTER TABLE EMPLOYEE MOVE ONLINE;
ALTER INDEX EMP_ID REBUILD ONLINE;
11. What is enq: TX – index contention ?
When lot of insert and delete operations happens on a table, contention might happen on the respective indexex.
Because, insert cause index splitting, if the transactions are accessing the index , during these splitting, then there will a waiting.
There are few solutions , which can be applied . But before doing changes, need to be tested thoroughly.
- Creating a reverse key Index.( This helps where only inserts happen, but might impact the range scan)
- Increase pctfree value( This will reduce index splitting)
12. What are different types of mutex wait events?
- cursor: mutex X
- cursor: mutex S
- cursor: pin S
- cursor: pin X
- cursor: pin S wait on X
- library cache: mutex X
- library cache: mutex S
13. Library cache lock wait event?
Below are some reason which might cause this wait event.
Reasons
- Small shared pool
- Less cursor sharing / i.e more hard parsing
- library cache object invalided and reloaded frequently
- Huge number of child cursor for a parent cursor ( i.e high version count)
- Non use of binds by application queries
- DDL during busy activity
Solutions:
- Increase shared pool size
- Always run critical DDLs during non-busy hours
- Avoid object compilations during peak time
- Check query with literates( Check cursor_sharing parameter)
14. Can a full tablescan cause db file sequential read?
It can happen , if you have chained rows.