
POSTGRES ARCHITECTURE & INTERNALS:
1. How connection is established in postgres?
The supervisor process is called postgres server( earlier it was known as postmaster) and listens at a specified TCP/IP port for incoming connections. Whenever a connection request comes, it spawns a new backend process. Those backend processes communicate with each other and with other processes of the instance using semaphores and shared memory to ensure data integrity throughout concurrent data access.
Once a connection is established, the client process can send a query to the backend process it’s connected to. The backend process parses the query, creates an execution plan, executes the plan, and returns the retrieved rows to the client by transmitting them over the established connection.
2. Explain the postgres architecture ?
3. What are some important background processes in postgres?
BGWriter -> It writes dirty/modified buffers to disk
WalWriter- > WAL buffers are written out to disk at every transaction commit. The default value is -1.
SysLogger:Error Reporting and Logging
Checkpoint
Stats Collector -> It collects and reports information about database activities. The permanent statistics are stored in pg_catalog schema in the global subdirectory.
Archiver ->. Setting up the database in Archive mode means to capture the WAL data of each segment file once it is filled and save that data somewhere before the segment file is recycled for reuse.
4. What are the memory components in postgres?
Shared Memory:
- shared_buffer ->
- − Sets the number of shared memory buffers used by the database server
- − Each buffer is 8K bytes
- − Minimum value must be 16 and at least 2 x max_connections
- − Default setting is managed by dynatune.
- − 6% – 25% of available memory is a good general guideline
- − You may find better results keeping the setting relatively low and using the operating system cache more instead
- wal_buffer ->
- Number of disk-page buffers allocated in shared memory for WAL data
- − Each buffer is 8K bytes
- − Needs to be only large enough to hold the amount of WAL data created by a typical transaction since the WAL data is flushed out to disk upon every transaction commit
- − Minimum allowed value is 4
- − Default setting is -1 (auto-tuned)
- clog buffer
Private Memory used by each server process:
- Temp_buffer -> for temp table operations.
- work_mem ->
- − Amount of memory in KB to be used by internal sorts and hash tables beforeswitching to temporary disk files
- − Minimum allowed value is 64 KB
- − It is set in KB and the default is managed by dynatune
- − Increasing the work_mem often helps in faster sorting
- − work_mem settings can also be changed on a per session basis
- maintenaince_work_mem ->
− Maximum memory in KB to be used in maintenance operations such as
VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY − Minimum allowed value is 1024 KB
− It is set in KB and the default is managed by dynatune
− Performance for vacuuming and restoring database dumps can be improvedby increasing this value
- autovacuum_work_mem ->
− Maximum amount of memory to be used by each autovacuum worker process
− Default value is -1, indicates that maintenance_work_mem to be used instead
5. When wal writer write data to wal segement?
6. When bgwriter writes data to disk?
7. What are some wal related parameter in postgrs.conf file?
max_wal_size – > It is the total size of wal segment(soft limit). If the this size is filled, then checkpoint will occurs.
wal_keep_segment
wal_keep_size =
max_wal_sender = 10 ( maximum number of wal sender process)
wal_level =
8. What is checkpoint? When checkpoint happens in postgres?
A checkpoint is a point in the transaction log sequence at which all data files have been updated to reflect the information in the log. All data files will be flushed to disk.
- pg_start_backup,
- CREATE DATABASE,
- pg_ctl stop|restart,
- pg_stop_backup,
- When we issue checkpoint command manually.
For periodic checkpoints below parameter play important role.
- checkpoint_timeout = 5min
- max_wal_size = 1GB
A checkpoint is begun every checkpoint_timeout seconds, or if max_wal_size is about to be exceeded, whichever comes first. The default settings are 5 minutes and 1 GB, respectivel
With these (default) values, PostgreSQL will trigger a CHECKPOINT every 5 minutes, or after the WAL grows to about 1GB on disk
9. Lets say your work_mem is 4MB. However your query is doing heavy sorting, for which work_mem required might be more than 4MB. So will the query execution be successful?
Yes it will be successful , Because it utilized the work_mem fully, it started using temp files.
10. What are the different phases of statement processing?
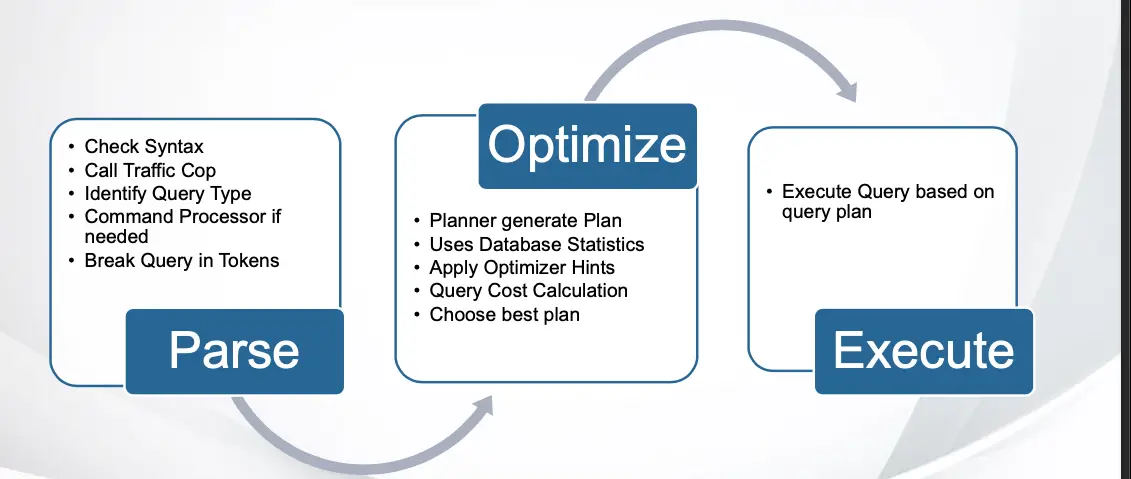
11. Which parameters controls the behaviour of BGWriter?
bgwriter_delay – size of sleep delay when number of processed buffers exceeded.
bgwriter_lru_maxpages – number of processed buffers after bgwriter delays.
bgwriter_lru_multiplier – multiplier used by bgwriter to calculate how many buffers need to be cleaned out in the next round.
These settings used to make bgwriter more or less aggressive – lower values of maxpages and multiplier will make bgwriter lazier, and higher maxpages and multiplier with low delays will make bgwriter more diligent.
12. Does postgres support direct i/o.?
Postgres doesnt support direct i/o.
13. How authentication happens in postgres?
pg_hba.conf file is used defining host based authentication methods. In this file, we define the details like host,database, ip address, user and method.
Different types of methods in pg_hba.conf file are .
- Trust: for this option users can connect to the database without specifying a password. When using this option one should be cautious.
- Reject: This option rejects a connection to a database(s) for a user for a particular record in the file.
- Password: this option prompts the user for a password before connecting to the database. When this method is specified the password is not encrypted between the client and the database.
- Md5: this option prompts the user for a password before connecting to the database. When this method is specified the client is required to supply a double-MD5-hashed password for authentication.
- rver.
- Ident – Obtain the operating system user name of the client by contacting the ident server on the client and check if it matches the requested database user name. Ident authentication can only be used on TCP/IP connections. When specified for local connections, peer authentication will be used instead.
If you are doing any changes to pg_hba.conf file, then you need to reload /restart the cluster for the changes to take place.
14. What is the significance of pg_ident.conf file?
Just like we have os authenticated db users in oracle. Here in postgres also we have similar concept. We can provide mapping of os user and postgres db user inside pg_ident.conf file.
15. What is this wal_level parameter , different values of wal_level?
- Wal_level determines how much information is written to the WAL
- The default value is replica, adds logging required for WAL archiving as well as information required to run read-only queries on a standby server
- The value logical is used to add information required for logical decoding
- The value minimal, removes all logging except the information required to recover from a crash or immediate shutdown
- This parameter can only be set at server start
16. What is visibility map in postgres?
Every heap relation(i.e table/index) have a visibility map associated with them. It holds the visibility of each page in the table file. The visibility of pages determines whether each page has dead tuples. Vacuum processing can skip a page that does not have dead tuples.
Every visibility map has 2 bits per page.
The first bit, if set, indicates that the page is all-visible( means those pages need not to be vacuumed)
The second bit, if set means, all tuples on this page has been frozen. ( no need to vacuum)
Note – > Visiblity map bits are set by VACUUM operation. And if data is modified ,bits will be cleared.
This condition helps in index only scan.
17. What is free space mapping(FSM) in postgres?
Each table/index has a Free space mapping file. It keeps information about which pages are free in the respective table/index . The extension of FSM file is .fsm .
When a tuple is inserted, postgres uses the FSM of the respective table, to select the page, where it can be inserted.
the FSM files are updated during insertion of new record.
The VACUUM process also updates the Free Space Map and usi
We can use pg_freespacemap extension to look into the freespace usage.
18. What is initial fork?
19. What is TOAST?
20. What happens in the background during vacuuming process?
21. What is transaction id wraparound? How to overcome it.
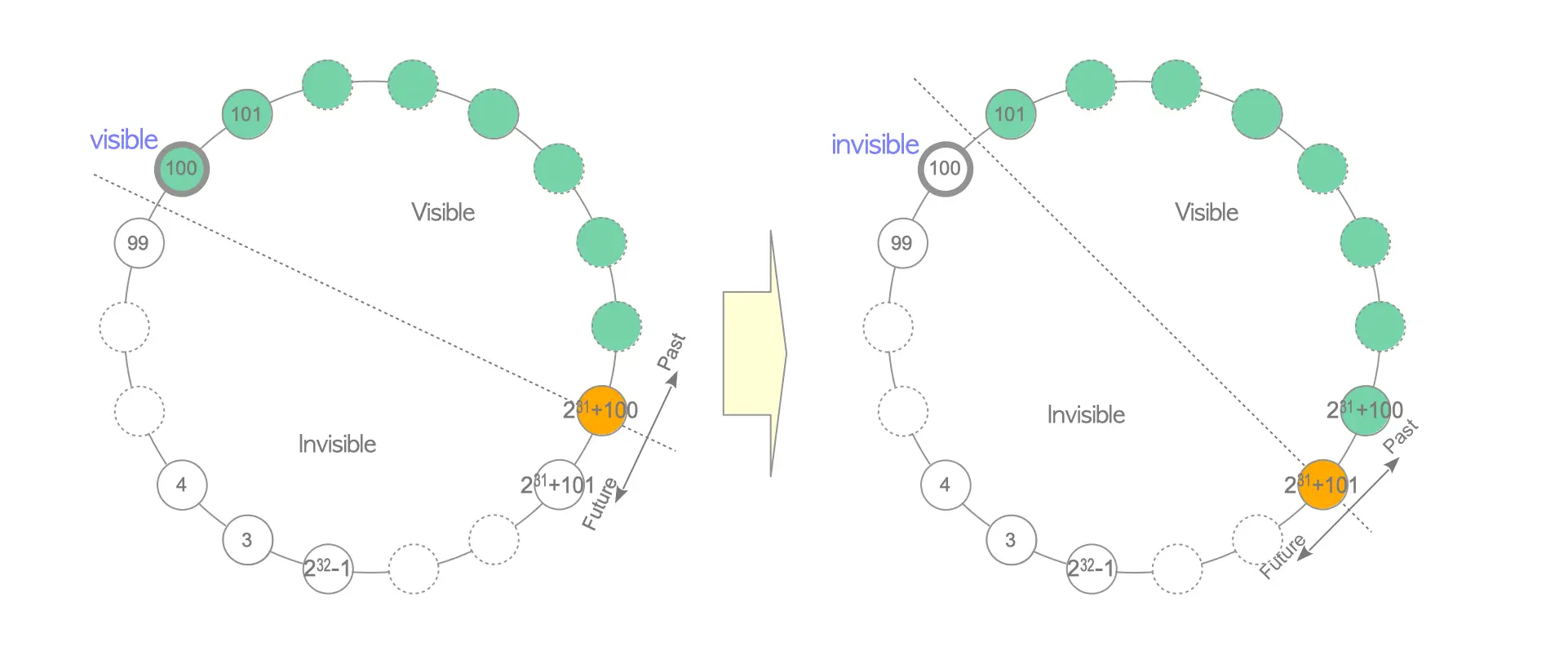
Assume that tuple Tuple_1 is inserted with a txid of 100, i.e. the t_xmin of Tuple_1 is 100. The server has been running for a very long period and Tuple_1 has not been modified. The current txid is 2.1 billion + 100 and a SELECT command is executed. At this time, Tuple_1 is visible because txid 100 is in the past. Then, the same SELECT command is executed; thus, the current txid is 2.1 billion + 101. However, Tuple_1 is no longer visible because txid 100 is in the future (Fig. 5.20). This is the so called transaction wraparound problem in PostgreSQL.
To deal with this problem, PostgreSQL introduced a concept called frozen txid, and implemented a process called FREEZE.
In PostgreSQL, a frozen txid, which is a special reserved txid 2, is defined such that it is always older than all other txids. In other words, the frozen txid is always inactive and visible.
In version 9.4 or later, the XMIN_FROZEN bit is set to the t_infomask field of tuples rather than rewriting the t_xmin of tuples to the frozen txid
22. What is the significance of search_path in postgres?
23. What is multi version concurrency control( MVCC)?
MVCC helps in currency control by maintaining multiple copies of same tuple, so that read and write operations same tuple doesnt impacts. Update in postgres means new row will be inserted and old row will be invalided( we can say delete followed by insert). And these old tuples can be visible to the other transactions depending upon the isolation level.
24. What are the advantages and disadvantages of MVCC?
Advantage is read consistency. Because of mvcc readers are writers dont block each other. If a a row has been modified by a user , but not committed . And if another user try to access that row, Then he will get the old committed data.
Disadvantage is , it causes bloating. Also it needs more data to keep multiple version of the data. If your database doing lot of DML activities, then postgres need to keep all the old transaction records also(updated or deleted) . And maintenance activity like vaccum need to be done remove the dead tuples.
25. Difference between pg_log, pg_clog, pg_xlog?
26. What is ctid?
It is similar to row_id in oracle.
The physical location of the row version within its table. Note that although the ctid can be used to locate the row version very quickly, a row’s ctid will change if it is updated or moved by VACUUM FULL.
27. What is oid?
Every row in postgres will have a object identifier called oid.
28. difference between oid and relfilenode?
29. Difference between postgres.conf and postgres.auto.conf file?
postgres.conf is the configuration file of the postgres cluster. But when we do any config changes using alter system command, then those parameters are added in postgres.auto.conf file.
When postgres starts , it will first read postgres.conf and then it will read postgres.auto.conf file.
30. What is timeline in postgres?
Timeline in postgres is used to distinguish between original cluster and recovered one. When we initialize the cluster, the timelineid will be set to 1. But if database recovery happens then it will increase to 2.
31. what is full page write in postgres?
full_page_write parameter is set to on ( default value).
When this parameter is on, the PostgreSQL server writes the entire content of each disk page to WAL during the first modification of that page after a checkpoint. This is needed because dirty write that is in process during an operating system crash might be only partially completed, leading to an on-disk page that contains a mix of old and new data. The row-level change data normally stored in WAL will not be enough to completely restore such a page during post-crash recovery. Storing the full page image guarantees that the page can be correctly restored.
32. What is xmin and xmax in postgres?
xmin and xmax are in row header.
When a row is inserted, the value of xmin is set equal to the transaction id that performed the INSERT command, while xmax is null.
When a row is deleted, the xmax value of the current version is labeled with the transaction id that performed DELETE.
The new row will have xmin same as that of xman of previous version.
33. What is a ring buffer in postgres?
Ring buffer is a temporary buffer area, used for performing large read,write operations on tables.
Ring buffer is allocated for below conditions.
- Bulk read
- Bulk write ( like CTAS, COPY FROM , alter table)
- During autovacuum process
Once these processes are completed, ring buffer is released.
34. What do you mean by postgres cluster?
Postgres cluster is a collection of databases stored in data_directory. One postgres instances managed one postgres cluster.
Note – Dont get confused with Oracle RAC cluster, where multiple instances run from multiple nodes for one database.
35. What is single user mode in postgres?
The primary use for this mode is during bootstrapping by initdb. Sometimes it is used for disaster recovery.
36. What is a timeline history file?
When we do a PITR , a timeline history file is created and it contains below information.
- timelineId – timelineId of the archive logs used to recover.
- LSN – LSN location where the WAL segment switches happened.
- reason – human-readable explanation of why the timeline was changed.
37. Are you aware of archive_library feature in postgres 15?
38. What is the use of wal files/segments?
39. What is LSN?
40. What are the three special transaction ids in postgres?
0 – > Means invalid txid
1 – > bootstrap txid(during initdb command)
2 – > Frozen txid
ADMINISTRATION:
1. What is the default port in postgres?
Default is 5432.
2. What is the default block size in postgres? Can we set different block size?
3. What is a tablespace?
A tablespace is used to map a logical name to a physical location on disk. In the simplest word, we can understand tablespace as a location on the disk where all database objects like table and indexes are stored.
It is also important to note that the name of the tablespace must not start with pg_, as these are reserved for the system tablespaces.
Tablespace list can be found using below command:
postgres=# select * from pg_tablespace;
(OR)
postgres=# \db+
4. What are the tablespaces created by default after installing postgres cluster?
Pg_global – > PGDATA/global – > used for cluster wide table and system catalog
Pg_default – > PGDATA/base directory – > it stores databases and relations
Whenever any user creates any table or index, it will be created under pg_default and this is the default_tablespace setting.
However you can change the default_tablespace setting using below one.
alter system set default_tablespace=ts_postgres;
5. What is the use of temporary tablespace?
It is used to store temporary objects like temporary table etc. But If we don’t set temp_tablespace parameter explicitly then , temporary objects will be created under pg_default tablespace.
postgres=# SELECT name, setting FROM pg_settings where name=’temp_tablespaces’;
6.What are the default databases created after setting up postgres cluster?
postgres=# select datname from pg_database;
datname
———–
postgres
template1
template0
7.What is the significance of template0 and template1 databases? What the difference between these two?
Whenever we create a new database , it creates is using the template1 database. And if you modify anything in template1 database like creating new extension in template1 database, then these changes will be reflected to other created databases.
Template0 – > No changes are allowed to this database. If you messed up your template1 database , then you can revert them by createing a new one from template0.
In the below screenshot, you can see for template1 , datallowconn is true, But template0 it is false.

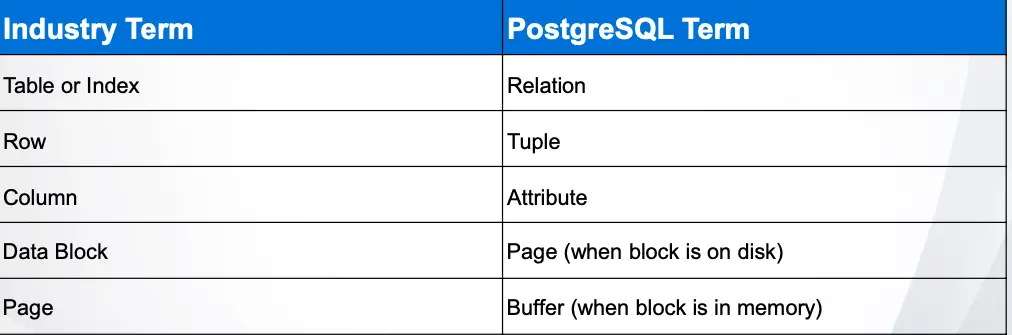
8. What are common database object names in postgres compare to industry terms.
9. Difference between user and schema in postgres?
If you are aware of oracle db, then you know that both user and schema are same . But in postgres both are different.
A schema is a collection of database objects. But a user is used to connect to postgres cluster. A single user can be used to connect to any database in the cluster( provider permission is give). However schema is local to that particular database.
Below diagram should clear your doubts
|
1
2
3
4
5
6
7
8
9
|
|-------------------------------------------|---|| PostgreSQL instance | ||-------------------------------------------| U || Database 1 | Database 2 | S ||---------------------|---------------------| E || Schema 1 | Schema 2 | Schema 1 | Schema 2 | R ||----------|----------|----------|----------| S || t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | |------------------------------------------------- |
10. Difference between role and user in postgres? Can we convert a role to user?
Role and user are almost same in postgres, only difference is , a role cannot login , But a user can. We can say like a user is role with login privilege.
And yes we can convert the role to a user.
alter role <role_name> nologin;
11. Difference mode to stop a postgres cluster using pg_ctl?
Postgres has 3 shutdown modes.
smart. – > It is the normal mode . i.e shutdown will wait for all existing connection to be terminated And it might take a lot of time. And no new connections will be allowed during this.
fast -> It terminates all existing sessions and performs checkpoint . It is comparably quick. But if there is lot of trnsactions that need to written to disk, then checkpoint might take lot of time.
immediate – > It will abort the instance. I.e it will terminate all existing session and shutdown the instance without performing checkpoint. It is the quickest . But upon instance startup , recovery will happen.
So if you have lot of pending transactions in your database, then the best way is perform checkpoint manually and then stop the server.
postgress#CHECKPOINT; – > Run as super user
enterprisedb$ pg_ctl stop -m fast
12. Can you give comparison of shutdown modes between oracle and postgres?
| ORACLE | POSTGRES |
| shutdown normal | smart |
| shutdown immediate | fast |
| shutdown abort | immediate |
13. Can we stop a particular database in postgres cluster?
No we cannot stop/start a particular database in postgres. We can only shutdown the postgres cluster.
14. What are foreign data wrappers? What is its use?
When we want to access data from a remote db ( can be any type of database oracle/postgres/mysql etc).
15. what is the use of share_preload_libraries in postgres.conf file?
Usually when we add extensions like pg_stat_statement, then we need to add the library path in the parameter shared_preload_libraries.
Because these extensions use shared memory, we need to restart the postgres cluster.
the reason we are preloading these libraries is to avoid the library startup time, when the library is first used.
16. what different types of streaming replications are present in postgres? And which parameters control that.
18.What is random page cost?
19.Difference between explain and explain analyze in postgres?
Explain – > Generates query plan by calculating the cost
Explain analyze -> It will execute the query and provides query statistics of the executed query. This gives more accurate plan details. Please be careful while running insert,update,delete like DML commands with explain analyze, as it will run the query and cause data changes.
20. What are the different datatypes in postgres?
Boolean
char,vchar,
int,float(n)
uuid
date
21. what is the maximum file size of table or index in postgres? Can we increase that ?
Max size is 1GB. If a table size is big, then it can spread across multiple files. lets says the file_name is 19870 . and once it reaches 1gb, a new file will be created as 19870.1 .
22. Is there a way in which we can rebuild/reorg a table online to release free space?
As we know vacuum full is used to rebuild table and it releases free space to operating system. However this method, puts an exclusive lock on the table.
So we can use pg_repack extension to rebuild a table online.
23. How pg_repack works internally?
24. How can i check the version of postgres?
cat PG_VERSION file.
or select pg_version();
25. What is the latest version of postgres in market?
Postgres 15.
26. While dropping a postgres database i am getting error? What might be the issue?
If you want to drop a database , then you need to fire the command, after connecting to a different database in the same postgres cluster with superuser privilege.
27. What are some key difference between oracle and postgres?
28. Between postgres and nosql database like mongodb , which one is better?
29. What is table partitioning in postgres? What are the advantages?
30. How you monitor long running queries in postgres?
we can use pg_stat_activities to track .
31. How to kill a session in postgres?
pg_terminate_backend(pid). pg_terminate_backend command send the SIGTERM signal to backend process. Where cas pg_cancel_backend() commands sends SIGINT command to backend process.
32. What is an extension in postgres? Which extensions you have used ?
pg_stat_statements
pg_track_settings
pg_profile
33. What are the popular tools for managing backup and recovery in postgres?
edb bart , barman etc
34. How can we use connection pooling in postgres?
pgbouncer is used for connection pooling
35. Which utility is used to upgrade postgres cluster?
pg_upgrade utility is used to upgrade postgres version.
36. How can we encrypt specific columns in postgres?
pgcrypto extension can be used
37. What is the use of pgbench utility?
38. What is difference between pg_cancel_backend vs pg_terminate_backend?
pg_cancel_backend will cancel the running sql query of that session . But session will be intact.
But pg_terminiate_backend will kill the session i.e the pid.
5. Do we have synonyms in postgres?
5. How can we convert a non partitioned table to partitioned table in postgres?
5. How can we convert a non partitioned table to partitioned table in postgres?
5. Can we create invisible index in postgres?
Yes in postgres, we can create hypothetical index. For that we need a third party extesion called hypopg
SELECT * FROM hypopg_create_index(‘CREATE INDEX ON t1 (a)’);
5. Suppose we have some views using a table and if drop that table, what will be the impact on those views?
5. Difference between open source installation and edb installation?
5. What is the difference between pgpool and pgbouncer?
Though both are connection pooling tools , they have few differences .
MAINTENANCE:
1. What is vacuuming in postgres?
Whenever tuples are deleted or becomes obsolete due to update, then they are not removed physicallly. These tuples are known as dead tuples. So vacuuming can be used to clear those dead tuples and release the space.
Basically two main tasks of vacuuming is :
- Removing dead tuples
- Freezing transaction ids
- Updates the FSM and VMs of tables.
2. Difference between vacuum and vacuum full?
VACUUM:
- Vacuum without full option, will reclaim the space and re-use it. However that free space is not returned to operating system.
- This will not put any exclusive lock on the system. So impact on the normal read write of the database.
- We can run this in parallel also. called as parallel vacuuming
Below is the VACUUM sequence:
- Puts a shared lock on the table.
- Scan all the pages to get the tuples and freezes old tuple if necessary.
- Remove the index tuple, pointing to dead tuples in table.
- Remove the dead tuples.
- Updates both FSM and VM of the respective table.
- Update the statistics and system catalog table.
VACUUM FULL
- Vacuum with full option, will reclaim more space and release the space to operating system.
- However we need additional storage , as it will rewrite the entire data to new disk file without any extra space.
- Also it will put exlusive lock on the table for which vaccuming is in progress.
- This method is much slower.
Below is the VACUUM FULL sequence:
- It puts exclusive lock on the table and create a new table.
- Copy the live tuples from old table to new table.
- After copy is done , it removes the old table files, updates the indexes and updates the VM and FSM.
3. What do you mean by vacuum freeze? And when we use it?
4. What is auto vaccuming in postgres?
Autovacuum triggers when dead tuples in a table reaches 20 percent of. table and it analyze the table when it reaches 10 percent of a table.
Below four parameters control the behaviour of the autovacumming.
autovacuum_vacuum_scale_factor = 0.2; autovacuum_analyze_scale_factor = 0.1; autovacuum_vacuum_threshold (integer)50 autovacuum_analyze_threshold (integer)50
At table level:
ALTER TABLE table_name SET (autovacuum_enabled = false);
1. How can i rebuild index?
for all indexes for a database:
REINDEX DATABASE <DB_NAME>;
For system tables of a database:
REINDEX system <db_name>;
for all indexes of a schema:
REINDEX SCHEMA schema_name;
for all indexes of a table:
REINDEX TABLE table_name;
for a particular index:
REINDEX INDEX index_name;
2. Will there be any impact on the database, if i run reindex command .
Reindex command, puts exclusive lock on the table. so for big indexes with live system, might be an issue.
However from postgres 12, REINDEX CONCURRENTLY OPTION IS available,which will do the reindex, without impacting the table.
2. What happens internally when we rebuild indexes?
REPLICATION:
1. Explain the basic streaming replication architecture.
- When we start the standby servers, the wal receiver process gets started on standby
- Wal receiver sends connection request to primary
- When primary receives wal receiver connection request, it starts walsender process and connection is established between wal sender and wal_receiver
- Now wal receiver send the standby’s latest LSN to primary.
- If standby’s LSN < Primary’s LSN, then the wal sender send the required WAL data to keep standby in sync.
- The received wal data is replayed on standby.
2. How can you check whether the database is primary or standby(replication).
method 1 :
We can check using below query. If the output is t means true i.e it is standby(slave server). If false means its primary or master.
select pg_is_in_recovery();
method 2:
You can run below query.
select * from pg_stat_replication;
3. I have a master and slave setup with streaming replication. Now I want to break the replication and open the standby server for some testing purpose and once the testing is done, the server again need to be a standby of that primary with replication enabled. How can i do that?
pg_rewind.
4. How pg_rewind works?
5. How can i do switchover in postgres without efm?
In postgres there is nothing called switchover, we can only do failover. but with efm we can do switchover using efm promote command.
6.Difference between standby.signal and recovery.signal?
recovery.signal: tells PostgreSQL to enter normal archive recovery . ( example – Point in time recovery).standby.signal: tells PostgreSQL to enter standby mode .
7. In streaming replication which additional processes run on primary and standby?
wal sender on primary
wal receiver on standby
8. What is the default streaming replication mode SYNC or ASYNC?
ASYNC is the default one.
9. Explain different types of replications methods available in postgres?
10. What is the significance of the parameter synchronous_commit?
Below are the values we can set to synchronous_commit.
- OFF – > Means, commit doesnt wait for transaction record to be flushed to disk.
- Local – > commit waits until the transaction record is flushed to disk.
- ON – > Commit waits , until standby servers mentioned in synchronous_standby_names , confirm that data is flushed to standby disk.
- remote_write -< Commit waits, until standby servers mentioned in synchronous_standby_names , confirm that data is written to os , but not necessrily the disk.
- remote_apply – > commit waits, until the standby servers mentioned in synchronous_standby_names apply those changes to the database.
11. Suppose A is primary and B is standby ? Now failover happened and then A becomes standby and B becomes primary. Now i want to make the A as primary again and B as standby . How can i achieve that?
12. Explain the architecture of EFM?
You need one master, one slave and one witness server.
13. What are some common reasons which cause streaming replication to fail.
14. What are the changes related to recovery.conf happened in postgres 12.
From postgres 12 onwards, the parameters of recovery.conf are now part of postgres.conf file. Instead of recovery.conf file, only two files are present, standby.signal and recovery.signal file( note both are empty files).
15. When we do failover, what happens in the timeline.
Timeline gets changed. i.e new timeline id is selected.
16. Like snapshot standby in oracle, can we use slave server in postgres as snapshot standby and revert it back to slave server once testing is done?
pg_rewind
17.Is there any mandatory parameter for pg_rewind to work?
18.Is replication possible between different versions of postgres?
19.What is replication slot?
Suppose the standby database is down for a long time . And if the wal_data on primary reached the max wal_keep_segment size, then it will start deleting the old wal data. As primary is not tracking the standby , if it removes the wal data which is not send to standby yet, then when we start the standby , it will fail .
So to avoid this issue, we can create replication slot. Replication slot will ensure that , the wal data which is not applied on standby will not be deleted.
5. Do you see any disadvantage of replication slot?
Orphan replication slot, can cause unbounded disk growth which is not required.
5. How many types of replication slots are there?
There are two types:
- Physical replication slot
- Logical replication slot
MONITORING:
BACKUP & RECOVERY:
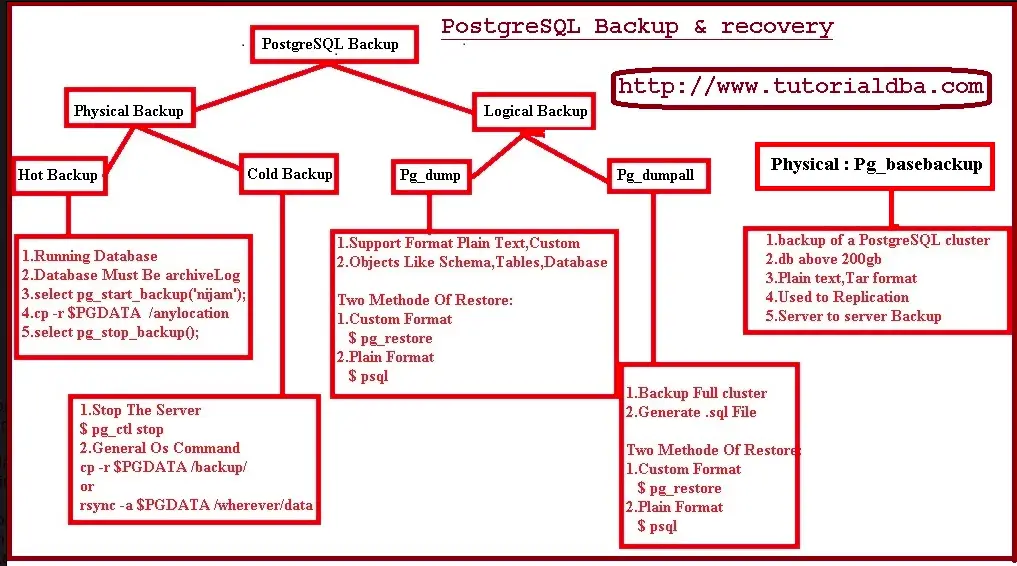
1. Explain different backup methods in postgres?
Reference – https://www.tutorialdba.com/p/postgresql-backup-recovery-overview.html
5. difference between pg_dump and pg_dumpall?
Both are logical backup utilities.
pg_dump -> Used for taking backup of databases, schema,table .backup format is like sql, tar file or directory
pg_dumpall -> Used for taking backup of complete cluster. backup format is sql .
5. Can i take backup of complete cluster using pg_dump?
5. What is the use of -globals options in pg_dumpall?
1. What pg_basebackup does internally?
1. Explain how postgres does crash recovery?
In case of crash of postgres instance, when the instance starts again, it will reply the wal file and recover the instance.
1. Can we take incremental backup using postgres? and how?
You can use third party tools like BART and barman.
1. Which important parameter is used for point in time recovery ?
1. What do you mean by continuous archiving in postgres?
17.Can I take export of only users using pg_dump?
3. Different type of indexes present in postgres ?
- BTREE
- HASH
- GIST
- BRIN
- GIN
4. Does create index puts lock on the table? If yes , then any workaround to avoid this locking?
Yes create index command puts exclusive lock on the table . So you can add CONCURRENTLY keyword, which will avoid the exclusive lock on the table.
5. What is index only scan in postgres?
PATCH & UPGRADE:
1. What is major version upgrade and minor version upgrade in postgres?
Major version upgrade Means when we do upgrade from postgres 12 to postgres 13 or 13 to 14 like that.
In major upgrade, the posgres binary and data_directory path gets changed.
pg_upgrade tool is used for major version upgrade.
Minor version upgrade: Means when we do upgrade from 13.1 to 13.3 .
In this case, pg binary and data_directory path will not be changed.
2. Explain how you do a major upgrade in postgres?
STEPS:
- Install new pg binary:
- Initialize new pg binary:
- shutdown both old and new pg cluster
- run pg_upgrade with -c option for verify
- run the actual pg_upgrade ( either with or without link option)
3. What is the user of link option in pg_upgrade?
while doing upgrade, if we are using link option, then data will not be copied from old directory to new directory. Only the symbolic links will be created in the new data directory.
For using link option, both old and new data_directory need to be in the same file system.
4. What are the advantages and disadvantages of using link option?
pros: As data is not copied, it saves a lot of time in upgrade( especially for large size database)
cons: If we use link option , then we wont be able to use the old cluster .
PERFORMANCE RELATED:
4. How do you find which objects are bloated in db?